ㅎㅎ 스타일트랜스퍼
한이 맺혀서 이번주는 요녀석이다..
절대 걸리면 안된다고 비니까 딱 걸려버린 문제..
그래서 공부하기..
소잃고 외양간 고치는 중
style transfer는 한 이미지에 다른 이미지의 스타일을 적용해서 새로운 이미지를 생성하는 방식을 말한다.
여러가지 방식 중 .. 내가 받은 질문인 사전 학습된 모델을 가져와 content이미지와 style 이미지를 입력으로 넣어서 이미지를 학습하는 방법에 대해 공부해보자!

모델 아키텍처는 다음과 같다.

input으로는 content image와 style image 2개가 들아가게 된다.
- content image : 네트워크에게 우리의 최종 이미지가 "어떻게 생겼으면 좋겠어!" 를 알려줌
- style image : 최종 이미지의 "텍스처나 색이 어땠으면 좋겠어!"를 알려줌
방식은 다음과 같은데
- 네트워크에 두 이미지를 통과시키고 feature map과 gram matrix를 계산한다.
- 최종 출력 이미지는 랜덤 노이즈(x)로 초기화 시킨다.
- forward, backward를 반복하여 계산해 gradient ascent를 이용해 이미지를 업데이트 한다.

시간이 지남에 따라 gradient ascent 과정에서 새로운 이미지를 생성하게 된다.
style image는 gram matrix를 사용하는데, 여러 layer의 feature map을 같이 확인하며 style을 추출하기 위함이다.
- style loss
논문에서 style representation을 feature map의 filter 간의 상관관계로 정의한다. 이 feature correlation을 gram matrix로 내적을 이용하여 계산한다.

gram matrix를 이용해 . 각층의 style image와 generated image의 style 차이를 squqre error를 정의한다.
- content loss
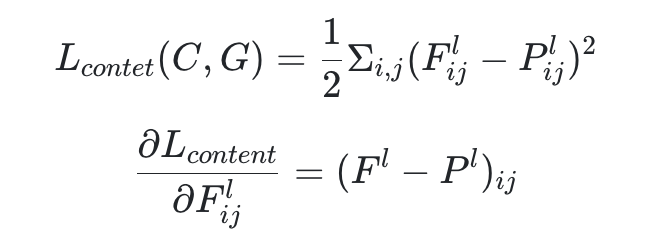
style image와 noise x에 대해서는 각 layer에서 content loss를 계산하게 된다. contents를 더많이 따라갈 것인지! 에 대해서 학습이 되는 것이다.
여기서 content reconstruction을 확인하면 깊은 층으로 갈수록 low-level feature 정보는 잃고, high-level feature 정보만 유지한다.
따라서 content loss를 계산할 때, 사용할 feature map의 층을 얕은 층과 깊은 층 사이 중간에서 골라야 한다고 한다.
최종적으로 이 둘의 loss를 합쳐 backprop을 통해 noise인 x를 업데이트하게 된다.

여기서 알파와 베타는 weigthting factor로 hyperparameter 이다.
📌 style transfer에서 BN을 쓰지않고 IN을 쓰는 이유는?
직관적으로 BN은 single sample이 아닌 sample batch의 feature statistics를 정규화하기 때문에 single style을 중심으로 나머지 batch를 정규화한다고 이해할 수 있다. 하지만 각 single smaple에는 서로 다른! 스타일이 있을 수 있기에 모두 동일한 style로 transfer를 하는 feed-forward style transfer 알고리즘은 바람직하지 않다.
반면에! IN은 각 개별 sample의 스타일을 target style로 normalize 할 수 있다. 나머지 네트워크는 원본 style information을 버리고 content manipulation에 집중할 수 있으므로 학습에 용이하다.
내가 대답 못했던 정확한 질문은
"style transfer에서 content loss와 style loss의 의미를 설명하세요" 였다.
간단히~ 다시 리마인드~
했습니당.
'모각코' 카테고리의 다른 글
| [모각코 6주차] 데이터베이스 SQL 고급 (2) | 2024.05.01 |
|---|---|
| [모각코 5주차] inductive bias (0) | 2024.04.03 |
| [모각코 3주차] Convolution Neural Network (0) | 2024.03.21 |
| [모각코 2주차] self-supervised learning (2) | 2024.03.13 |
| [모각코 1주차] VAE를 공부하면서! (2) | 2024.03.06 |