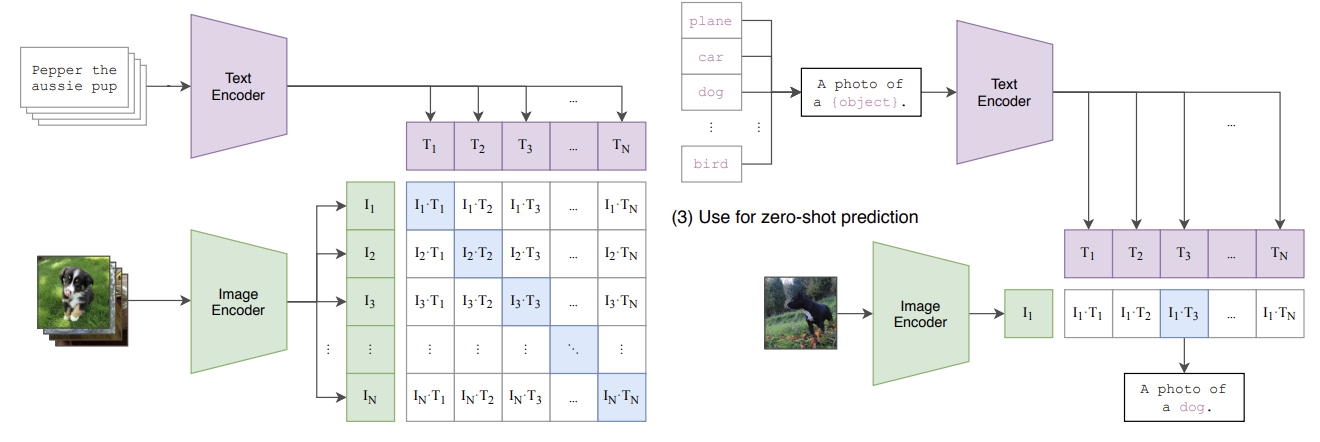
뭔가 속시원하게 이해하기 어려웠던 논문 열린 결말 같은 결론.. 내 언어로 풀어서 이해하면 자칫 오개념이 될 것 같았던 논문.. 새벽 세 시에 리뷰해봅니다... AbstractDNN이 매우 큼에도 불구하고 성공적인 DNN은 train과 test의 성능 차이가 매우 작다.이 말은 일반화 오류가 작다고 표현일반화: 보지 않은 새로운 data에서도 잘 작동하는 것⇒ 일반화 오류가 작다는 건 모델이 단순히 크기만 커서가 아니라 그 안에 존재하는 모델의 feature와 학습하는 방법이 성능 차이를 줄이는데에 기여한다!위와 같은 접근법, 전통적인 접근법 (feature 학습이나 정규화)는 large NN의 일반화 성능을 충분히 설명하지 못한다는 걸 실험적으로 보여줌sota ResNet for image classi..