처음 써보는 논문 리뷰 포스팅!
논문을 읽은 나의 견해! 를 남긴다기보다는 (남기면좋겠지) 어떤 내용인지! 무엇을 말하고자 하는지! 를 살펴보고~
가능하다면 느낀점들도 적어보려고 합니다.
포스팅된 논문리뷰 글들은 아마 대부분! [EECS 498-007/598-005] 강의에서 언급되거나 레포로 걸려있는 것들 입니당.
첫번째 논문 Vaswani et al, “Attention is all you need”, NeurIPS 2017 은 13강 Attention 강의에서 등장한다.
Abstract
Sequence model은 복잡한 순환 또는 CNN을 기반으로 하며, 이는 encoder와 decoder를 포함하고 있다. 성능이 우수한 모델들은 attention 매커니즘을 통한 encoder와 decoder를 연결하고 있다.
여기서 우리는 새로운 간단한 network architecture인 Transformer를 제안하는데, Transformer는 attention 매커니즘에 기반하며, recurrence와 convolutions를 완전히 배제한다. 2개의 기계 학습 번역 작업 실험 결과, 이 모델들이 품질에서 뛰어나며 병렬화가 더 쉽고, training에 훨씬 더 적은 시간이 필요함을 보여준다.
해당 모델은 WMT 2014 영어-독일 번역 작업에서 기존 모델보다 2BLEU이상 향상된 28.4 BLEU를 달성하였다. 또한 WMT 2014 영어-프랑스 번역 작업에서 8개의 GPU로 3.5일 동안 train후 41.0 BLEU 점수를 달성해 문헌에서 최고 성능 모델을 수립하였다.
** WMT : Workshop on Statistical Manchine Translation의 약자로 2006년 부터 개최된 기계 번역과 관련된 연구와 개발을 촉진하기 위한 워크샵.
Introduction
RNN, LSTM, gated RNN은 언어 모델링 및 기계 번역과 같은 순차적인 모델링에서 최첨단 접근 방식이 되었다. 이후로도 많은 노력들이 계속 되어 순환 언어 모델 및 encoder-decoder 아키텍처의 한계를 더욱 넓히고 있다.
순환 모델들은 일반적으로 입력 및 출력 sequence의 위치에 따라 계산하여 이전의 hidden state인 ht-1과 t를 입력으로 숨겨진 상태 ht를 생성한다.
이러한 본질적인 순차적 특성으로 인해 train동안의 병렬화가 불가능하고, 이는 sequence의 길이가 길어질수록 메모리 제약으로 인해 배치가 제한되는 상황에서 중요해진다. 최근 연구에서는 인수분해 기술이나 조건부 계산을 통해 계산의 효율성을 크게 향상시켜 메모리 제약의 문제점도 크게 향샹시켰지만 순차적 계산의 문제점은 여전히 존재한다.
Attention 메커니즘은 다양한 작업에서 sequence modeling의 필수적인 부분이 되어 입력 또는 출력 sequence 길이의 관계없이 의존성 모델링을 할 수 있게 해준다. 그러나 대부분의 경우 A decomposable attention model를 제외하고는 이러한 attention 메커니즘이 RNN과 함께 사용된다고 한다.
그래서 여기서는 RNN을 배제하고 입력과 출력 간의 의존성을 가지는 attention 메커니즘 아키텍처인 Transformer를 제안한다. 이는 훨씬 더 많은 병렬화를 허용하며 8개의 P100 GPU에서 12시간 동안 훈련된 후에도 번역 품질에서 새로운 최첨단 기술에 도달할 수 있다고 한다.
Model Architecture
대부분의 모델은 encoder-decoder의 구조를 가지고 있다. 여기서 encoder는 (x1, x2 ... xn) sequence를 z인 (z1, ,,, zn)으로 매핑하고 주어진 z는 decoder의 출력 sequence (y1, y2 .. yn)을 한 번에 한 요소씩 생성한다.
3-1. Encoder and Decoder Stacks
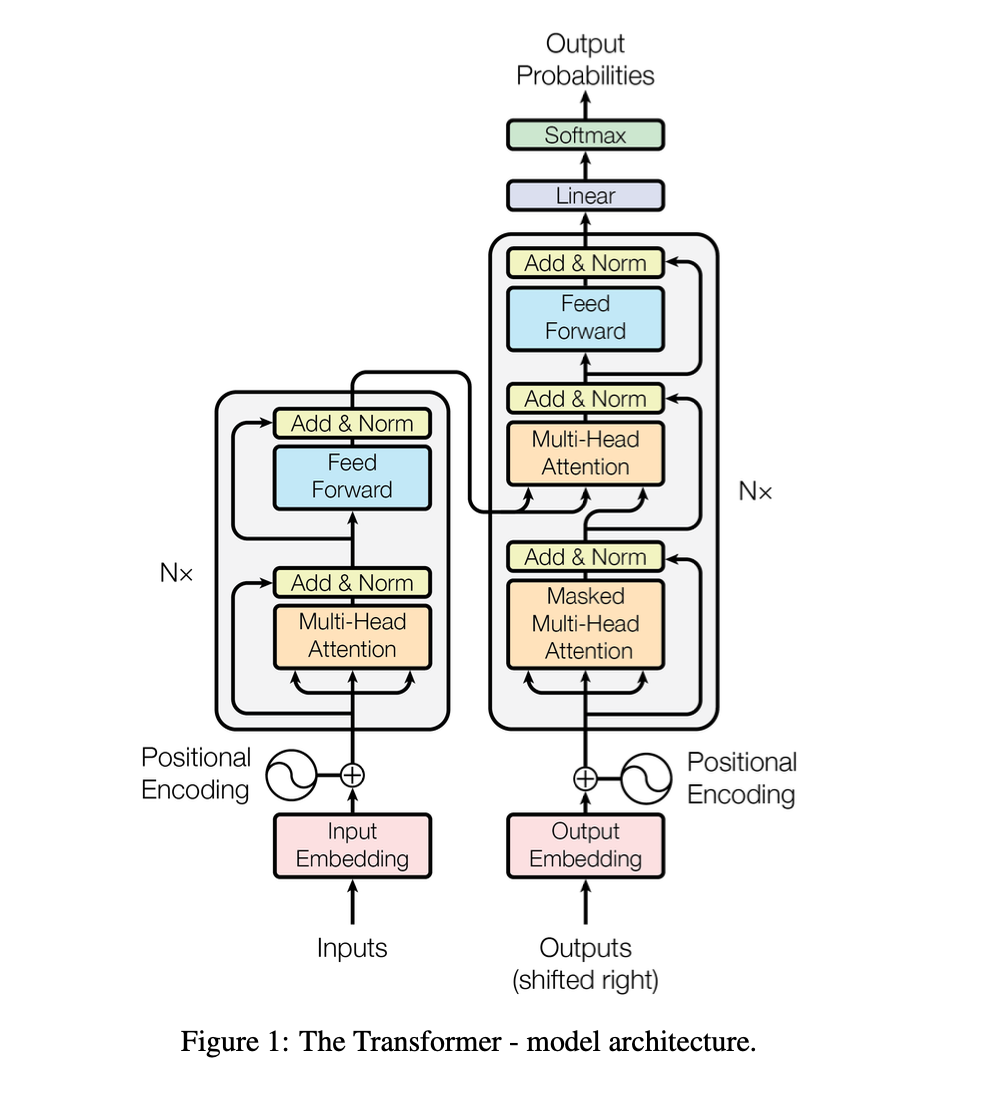
encoder는 6개의 동일한 layer로 구성된다. 각 레이어는 두 개의 하위 레이어로 이루어져 있다.
첫번째는 muilthead self-attention이고, 두번째는 position-wise fully connected feed-forward network 이다. 각각의 두 하위 레이어 주위에 residual connection을 사용하고 이후 레이어에 정규화를 적용한다. 각 하위 레이어의 출력은 LayerNorm(x + Sublayer(x))이다. 여기서 Sublayer(x)는 하위 레이어 자체에서 구현된 함수이다. 이러한 residual connection을 용이하게 하기 위해 모델 내의 모든 하위 레이어와 임베딩 레이어는 dmodel = 512의 차원의 출력을 생성한다.
decoder는 마찬가지로 동일한 6개의 layer로 구성되어있다. 3번째 sublayer에서는 encoder stack에 출력에 대한 multihead attention을 수행한다. 또한 각 layer마다 residual connection이 있고 그 후에 정규화가 이루어진다. 더하여 decoder stack의 self-attention sublayer를 수정하여 연이어 나오는 위치에만 어텐션 할 수 있도록 하고 있다. masking을 사용해 이후의 값이 아닌 이전의 값에 출력이 의존하도록 하고있다.