노션에 정리했던 것 주섬주섬 주어오기
오늘은 CLIP 당첨
오개념이있을수있음을주의!
행복한 하루 되십쇼
Abstract
이전에는 사전에 정의된 고정된 객체 카테고리를 예측하도록 훈련
이러한 형태의 supervision(지도학습)의 경우 other visual concept을 지정하려면 (language) 추가적인 레이블이 지정된 데이터가 필요
→ 반면, 이미지와 관련된 raw text로 부터 직접 학습하자?
⇒ 추가적인 데이터셋을 활용하지 않고도 특정 task를 위해 추가적인 데이터셋으로 학습한 기존 모델들과 견줄만한 성능이 나온다!
Introduction and Motivating Work
nlp 분야에서 raw text를 이용하여 사전학습하는 방법이 계속 연구되고 있음
- masked language modeling → task-agnostic 한 학습은 모델이 대규모 데이터를 이용해 학습할 수 있도록 함
- text-to-text → 태스크마다 다른 토큰을 사용하는 추가적인 작업 필요 x
⇒ 위 두가지 방법을 모두 적용한 GPT3의 경우 labeled dataset없이도 다양한 task에서 좋은 성능
labeling된 적은 양의 고품질 데이터셋보다 많은 양의 unlabeled된 데이터가 더 학습에 용이함을 시사
→ 그럼 cv에서도 웹 상에서 수집된 데이터로부터 사전학습을 하는 방식을 적용할 수 있지 않을까!
- prior work
- Learning Visual N-Grams from Web Data, Li et al., 2017
- 등등
- 사실 text로 부터 Image representation을 학습시키는 연구는 다른 것에 비해 성능이 크게 좋진않아
- but, focus more narrowly scoped + weak supervision → 성능개선
- weak supervision?
- 완벽하고 정확한 label 대신 불완전하거나 부정확한 nosie가 포함된 label을 사용하는것
- 레이블링의 시간과 비용을 줄이기 위해 타협을 보는 거?
- ex) 해시태그, 웹 크롤링 등
- 왜? 왜 성능이 높아질까?
- data scale의 차이!
- weak supervision?
- gold-label vs raw text
- 타협의 한계가 있다.
- 클래스 수가 고정적이라 세상의 모든 시각적 개념?을 표현하기엔 부족함
- 하지만 자연어의 경우 시각적 개념을 표현할 잠재력이 있으며 클래수 수를 초월 가능
- both static softmax classifier의 한계
- zero-shot 성능의 저하
- we close this gap and study the behaviors of image classifiers trained with natural language supervision at large scale.
- 자연어와 이미지를 결합하여 dynamic input + general train을 기대
- CLIP → contrastive Language-Image Pre-training
- competitive with prior task (기존 image net)
- linear-probe learning을 통하여 확인함
- 이는 pretrained model의 표현?을 평가하는데 사용하는 방법
- 모델의 파라미터는 고정하고 선형분류기만 학습해서 분류를 수행 → 일종의 downstream task 처럼?
- Image Net 모델보다 더 높은 성능 + computationally effcient
- zero-shot CLIP → 동일한 정확도를 가지는 모델보다 더 robust 함.
- competitive with prior task (기존 image net)
Approach
Natural Language Supervision
- 본 연구의 핵심은 natural language를 이용한 supervision
- 이 전에도 다양한 용어로 비슷한 연구가 진행되었음 (unsupervised, self-supervised, weakly 등)
- 자연어를 이용하면 gold label과 같은 annotation이 필요로 하지않아 scale을 키우는데 이점
- 또한 단순히 image-to-text를 just train 하는 것이 아니라 모델이 이미지에 대해 더 깊게 이해할 수 있게 하여 zero-shot transfer의 성능도 기대할 수 있게 됨
- 이미지와 text를 연결하는 방법? 을 배우는 느낌이라
Creating a Suffciently Large Dataseet
이전 연구에서 사용하던 데이터셋 (MS-COCO, Visual Genome, YFCC100M) 들은 양질의 데이터셋이지만 양이 작아
→ 따라서 새로운 dataset을 만들자
- WebImageText
- 약 4 억개의 (image, text) 쌍으로 구성되어 있으며 인터넷에서 수집한 데이터
Selecting an Efficient Pre-Training Method

- 기존 연구에서는 imagenet에서 매우 많은 gpu 메모리를 사용→ 효율성을 고려하자
- 또한 기존 연구에서는 문장을 예측할 때 단어의 순서까지 정확히 맞추는 task 였음
- 근데 이 경우 contrastive model 과 같은 성능에서 더 많은 compute 가 필요
- 또한 기존 연구에서는 문장을 예측할 때 단어의 순서까지 정확히 맞추는 task 였음
- 따라서 순서를 고려하지않는 bag-of-words encodeing 으로 contrastive learning을 진행
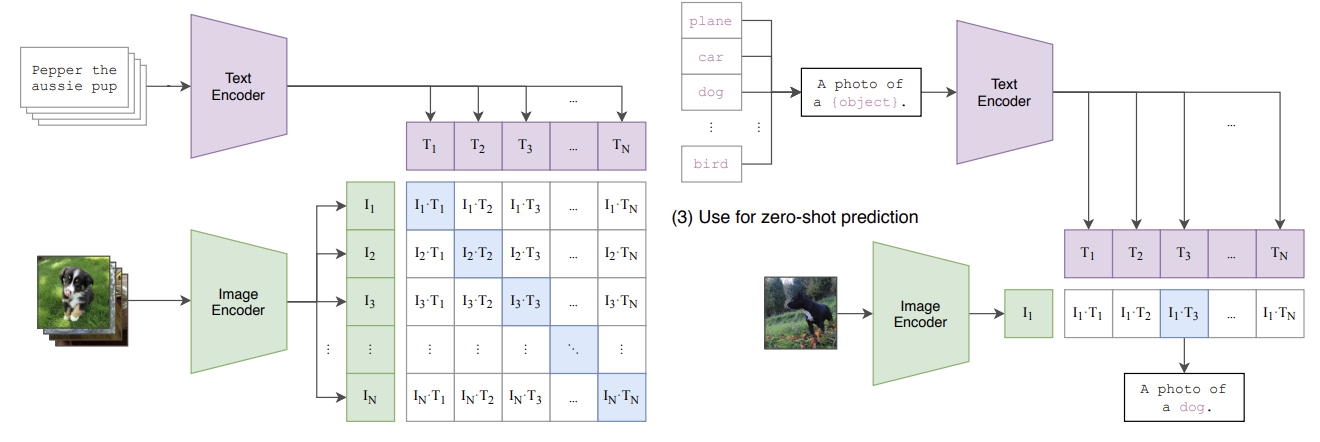
학습방법
- 배치사이즈 N → N 개의 (image, text) pair가 존재
- N 개의 텍스트 벡터와 N 개의 이미지 벡터의 코사인 유사도를 구함
- 총 N^2의 값이 나옴
- N 개는 실제 (image, text)에서 나온 값
- N^2 - N 개는 다른 (image, text)에서 나온 값
- 이 유사도 값들을 이용하여 cross-entropy 값을 최적화
- 학습 데이터 수가 많아서 overfitting은 고려하지 않음
- ImageNet weights나 pre-trained weights를 사용하지않고 scrach 로 학습
- representation과 contrastive embedding space 사이에 linear projection 사용
- 셀슈에서 썻던 non-linear projection head를 생각햅바
- 왜?
- non-linear 없이도 충분히 성능을 달성
- → co-adaptation 되었을 것이다!
- 모델의 뉴런?이 다른 뉴런에 의존해서 따라가는거?
- 그니까 ReLU 이런 걸 안 썻다는거야? → 그건 아닌거 같은데
- text transformation func Tu 를 제거
- 이 함수는 텍스트에서 단일 문장?을 균일하게 sampling 하는 역할
- 근데 CLIP에서는 이미 single sentence로 구성
- image transformation func Tv 도 간소화
- 기존에는 많은 방법의 image argumentation 적용
- but, random square crop만 적용
- learnable temperature parameter
- 이는 softmax smoothing 을 제어
- 작으면 sharp (특정 클래스에 높은 확률이 집중) , 크면 soft
- 기존에는 hyperparameter로 튜닝 또는 직접 지정
- leanable parameter로 지정
- ex) 데이터가 복잡하면 커져서 soft하게, 명확하면 작아져 분포가 날카롭도록?
- 이는 softmax smoothing 을 제어
Choosing and Scaling a Model
- image encoder에 대한 2가지 architecture
- Res-Net50
- gap → attention pooling 으로 대체
- width, depth, resolution 모두 확장 → 성능우수
- ViT
- add layer normalization
- patch와 poisition embedding 사이에
- add layer normalization
- Res-Net50
- text encoder 는 transformer 사용
- ResNet 너비에 맞춰줌 → 위에서 resnet은 모두 확장시켰으니 거기 너비에 맞춰서 조정하는 느낌
- 깊이는 증가시키지 않았는데, CLIP의 성능이 text encoder 크기에 less sensitive
Training
- 5 가지 ResNet 모델, 3가지의 ViT 모델 사용
- minibatch size: 32,768
- gradient checkpointing
- 중간 활성화 값을 모두 저장하지 않고 일부만 저장
- half-precision Adam statistics
- half-precision stochastically rounded text encoder weights
CLIP에서 말하는 zero-shot?
일반적으로 생각해볼때, zero-shot learning이라 함은 보지않은 data에 대해서 잘 맞추는 경우 라고 직관적으로 이해된다.
내가 CLIP을 공부할 때 가장 의아했던 건, 분명 본 class 인데 왜 zero-shot이라고 할까? 였다.
이 clip 이후에 등장하는 zero-shot은 specific data 를 보지 않은 경우를 말하는 것 같다.
결국 zero-shot이 가능해질 수 있는 건 WebImageText라는 대량의 데이터셋을 사용함이 가장 큰 기여를 했던 것
CLIP의 contribution
- text와 Image를 동시에 학습하는 멀티모달
- contrastive learning을 통해 멀티모달 관계를 학습
- zero-shot learning
- 특정 task에 대한 fine-tuning 없이도 텍스트의 설명 만으로 image classification이 가능함
- large scale dataset
- (text, image) pair의 대규모 데이터 셋으로 일반화 성능을 갖출 수 있었음