점심먹고 레전드 졸린 스타트
뭐 난 만날 졸리고 각박하고 춥대
(사실인걸 어케)
그렇지만 오늘 좋은 점을 꼽자면..
오전부터 짱 많이 웃ㅇ엇고..
얼큰만둣국 맛있엇구
5시간 숙면에 비해 나름 카페인 없어도 될 정도야
화이팅해보자구
포스팅 완료할 수 있을까? 히히
이번 강의는 하드웨어와 쏘프트웨어!
- Hardware

컴퓨터 내부 본체를 살펴보면 CPU와 GPU를 만나볼 수 있다.
CPU (Central Processing Unit)
- 일반적인 컴퓨팅 작업을 수행 -> 운영처제, 응용 프로그램 실행, 파일 관리 등
- 적은 수의 코어를 가지고 있으며 코어 각각이 독립적으로 명령어를 처리하는 구조
- 다양한 애플리케이션에 사용되며 단일 쓰레드 성능이 중요한 작업에 적합
GPU (Graphics Processing Unit)
- 주로 그래픽 및 병렬 처리 작업에 특화
- 많은 수의 작은 코어를 가지고 있어 병렬 처리에 유리 -> 대량의 데이터 동시 처리 가능
- 주로 그래픽 작업에 쓰임 -> 딥러닝 및 기계학습 분야에서도 중요

하드웨어에서 유명한 두 친구가 있는데, 주로 그래픽 카드 가속화 및 프로세서를 제조하는 기업이다.
하지만 딥러닝 분야에서는 NVIDIA가 훨씬 널리 쓰이고 있는데, 이는 AMD가 딥러닝을 위한 범용 컴퓨팅에 활용되는 software stack이 NVIDIA 만큼 많이 발전하지 못 했다고 한다.
더하여 NVIDIA는 CUDA라는 병렬 컴퓨팅 플랫폼을 제공하여 과학 계산, 딥 러닝, 기계학습분야에서 GPU 가속을 지원하고 있다고 한다.
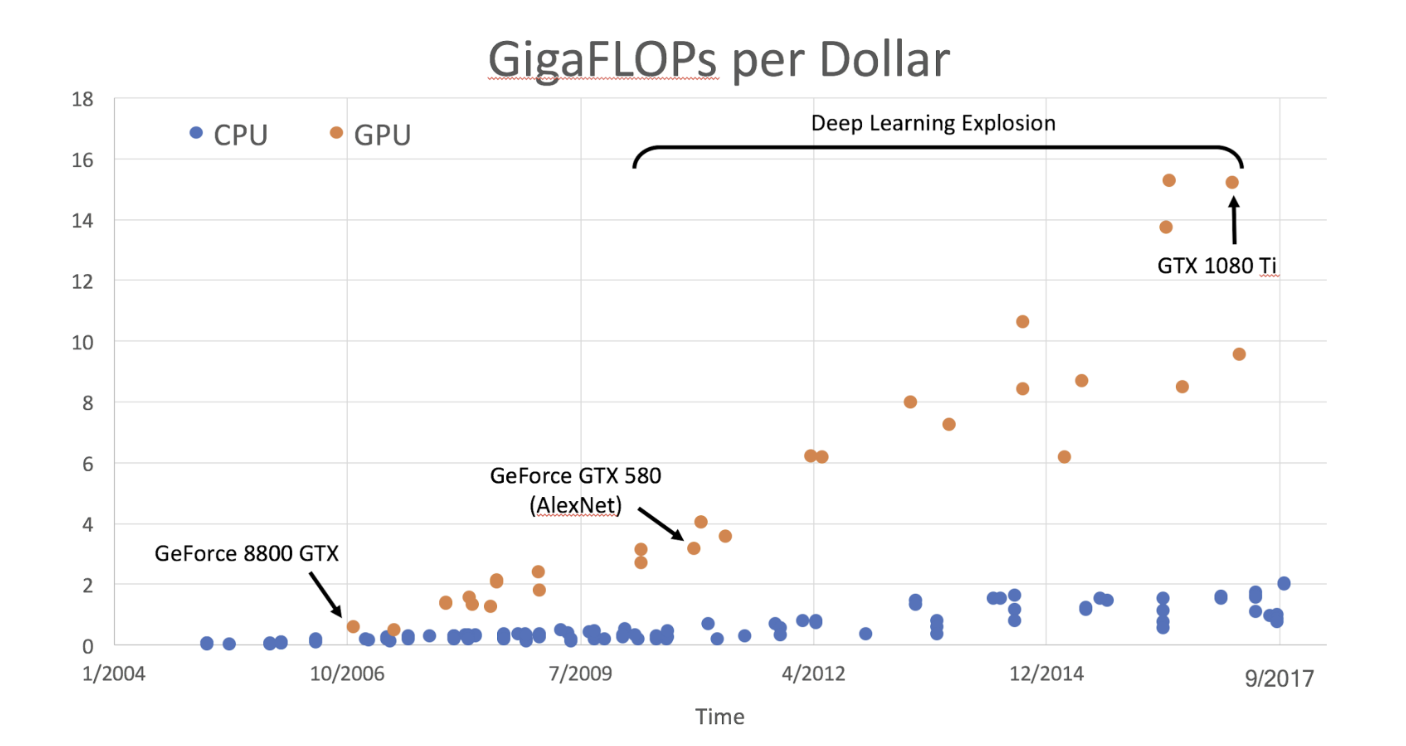
FLOPs란 Floating point Operations Per Second의 약자로 초당 얼마나 많은 부동 소수점 연산을 할 수 있는 지를 나타낸다.
앞선 8강을 보면 FLOPs를 다루었는데, 위 그래프를 보면 파란색 점이 CPU, 주황색 점이 GPU를 나타내고 있다.
2017년까지인 오래된 자료이지만 시간이 지남에 따라 둘 다 비용 대비 성능이 좋아지고는 있지만 특히 GPU가 엄청나게 치고 올라가는 것을 볼 수 있다.
2011년 전으로는 GPU가 컴퓨터 게이밍 관련하여 활용이 되었다면, 그 이후에는 딥러닝에 많이 활용되었다고 한다.
CPU와 GPU의 특징들을 잠시 살펴보면,

CPU -> AMD에서 나온 CPU
- core 16개 -> 개수는 작지만 각각의 코어는 아주빨라
- 3.5 GHz의 Clock Speed
- memory -> RAM으로 분리되어생각함
- 초당 4.8T 만큼의 floating point 연산을 함
- * FP32 -> 32bit의 실수 연산 (single precision)
GPU -> NVIDIA 에서 나온 RTX 모델
- core 4608개 -> 개수가 많지만 각각 코어는 조금 느려 -> 특정한 연산에 대해서만 작동(?)
- 1.35GHz의 Clock Speed
- 그래픽 카드 안에 memory가 있기 때문에 성능 중 하나로 취급(?)
- 초당 16.3T 만큼의 floating point 연산
위 특징들을 보면 CPU는 코어 당 성능이 중요한 연속적인 작업에서, GPU는 여러 코어를 사용하는 것이 가능한 병렬적 작업에서 좋다.
이제 딥러닝에서 강자였던 GPU에 대해서 더 자세히 알아보자.
위에서 설명했던 RTX 모델인데,

파란색 상자 부분이 memory 부분인데, 2GB가 12개가 있는 4개씩 3군데 있는 구조이다.
중간에 있는 빨간색 상자 부분이 processor 부분이다.
안쪽을 확대해서 보면 이렇게 복잡한 구조로 되어있다.
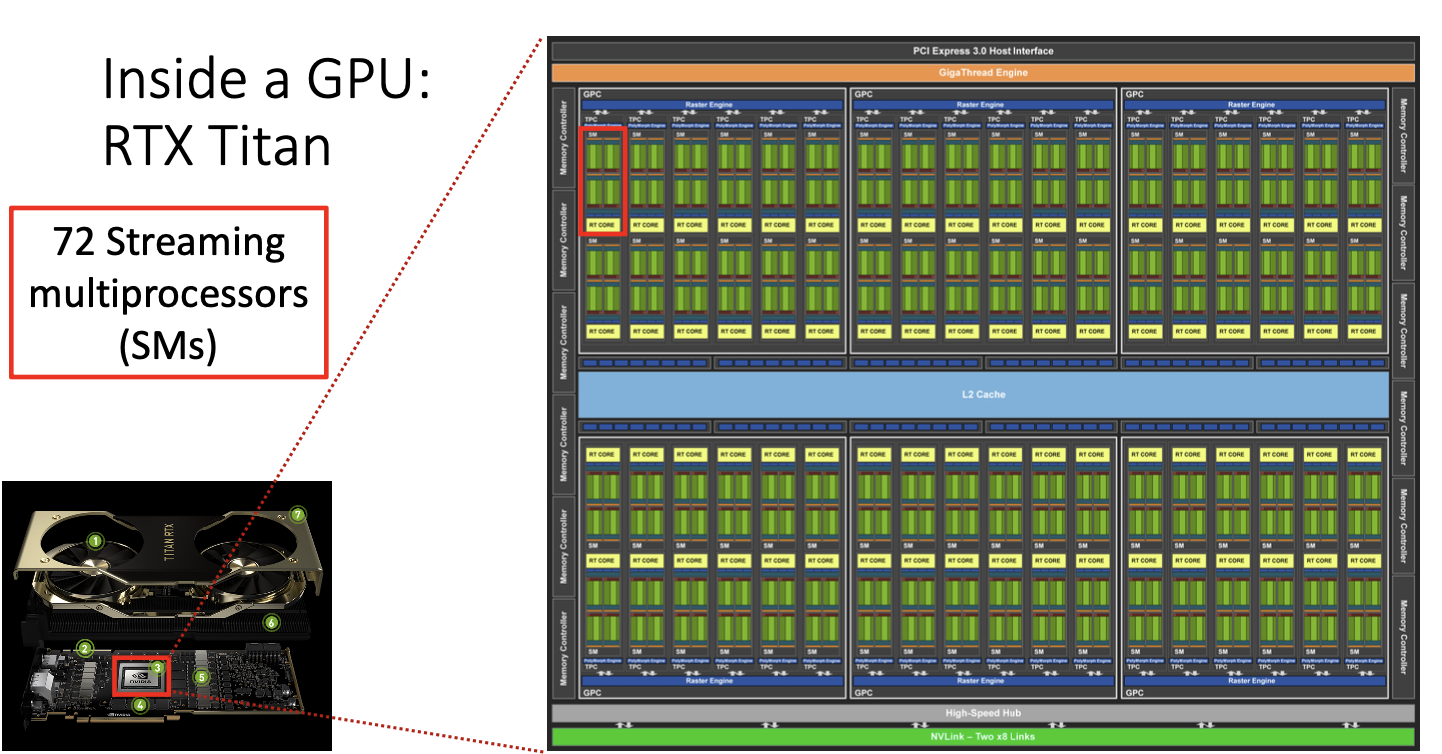
복잡해 보일 수 있지만 동일한 operation을 연결한 것으로 볼 수 있다.
설계를 보면 GPU processor와 memory를 최대한 붙여서 설계한 것을 볼 수 있고, 위 빨간색 상자 하나를 streaming multiprocessor라고 하는데, 이 것이 72개가 있는 구조이다.
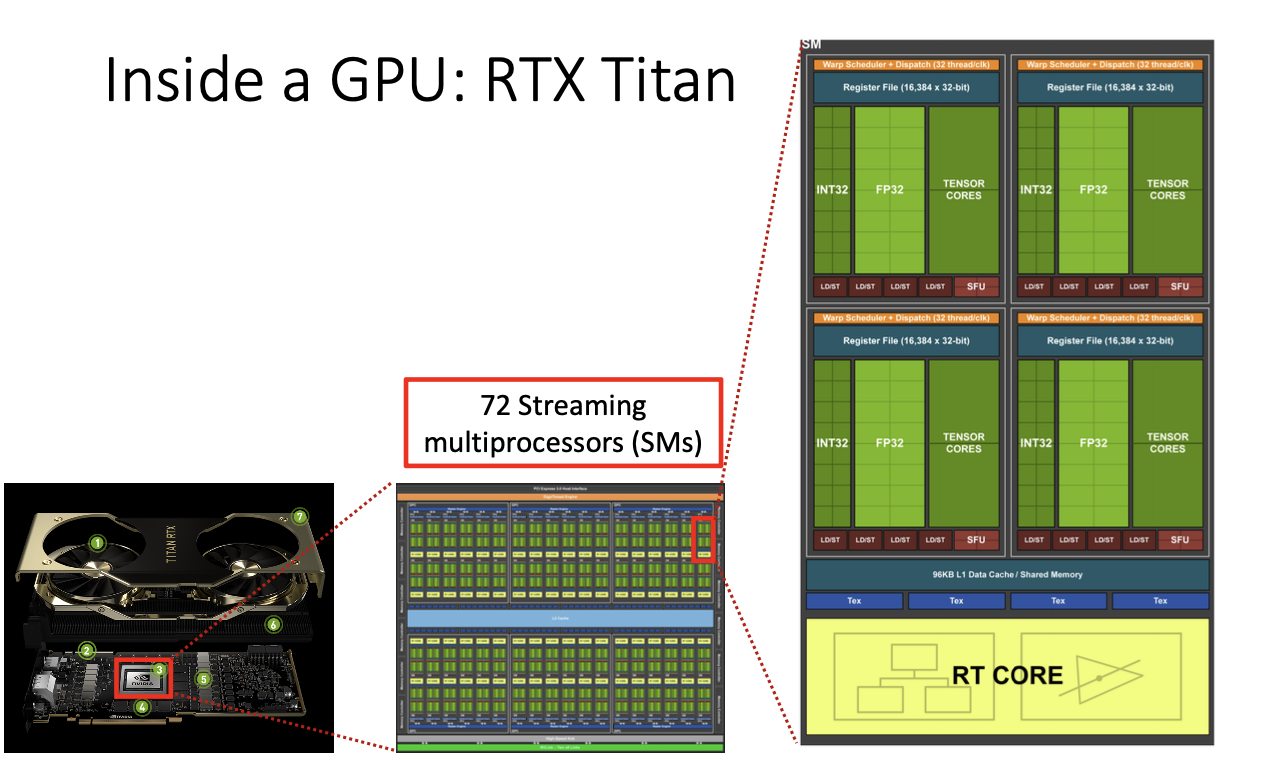
그 processor 하나를 들여다 보면 위와 같은 사진처럼 되어있고, 정수 연산, 실수 연산. tensor core 와 같은 3부분으로 나누어져 있다.
여기서 floating point연산을 주로 하는데,

하나를 뜯어보면 single precision의 floating point 연산을 할 수 있는 64개의 core가 있다. 이를 우리는 shader processor 또는
CUDA core라고 한다.
이 것의 총 연산을 구해보면 위의 식과 같고 최종적으로 초당 16.3조 개 만큼의 연산을 한다는 것이다.
*참고로 K = 10^3, M = 10^6, G = 10^9, T = 10^12를 나타낸다.
Tensor core도 자세히 살펴보면,

총 8개의 Tensor core가 존재하는데, Tensor core란 special hardware라고도 한다.
이는 주로 행렬 연산을 가속화하기 위해 설계된 것으로 곱셈에서는 FP16 형식의 연산을 수행한고 더할때만 FP32를 사용한다. (혼합연산)
*FP16은 더 낮은 정밀도의 부동 소수점 수를 사용하므로 연산이 빨라지지만 일부 정밀도 손실이 발생할 수 있다는 단점도 있음!
동작 원리는 4x4 행렬에 대한 행렬 곱셈을 수행하는데 이것은 큰 행렬을 4x4의 작은 블록으로 나누고, 이러한 작은 블록에 대한 행렬 곱셈을 병렬척으로 처리하는 방식으로 이루어진다. -> 효율적으로 연산하기!
그래서! 아까 위 표에서 GPU에 tensor core를 추가하여 나타낼 수 있다.

따라서 tensor core의 등장으로 TITAN V가 등장했고,
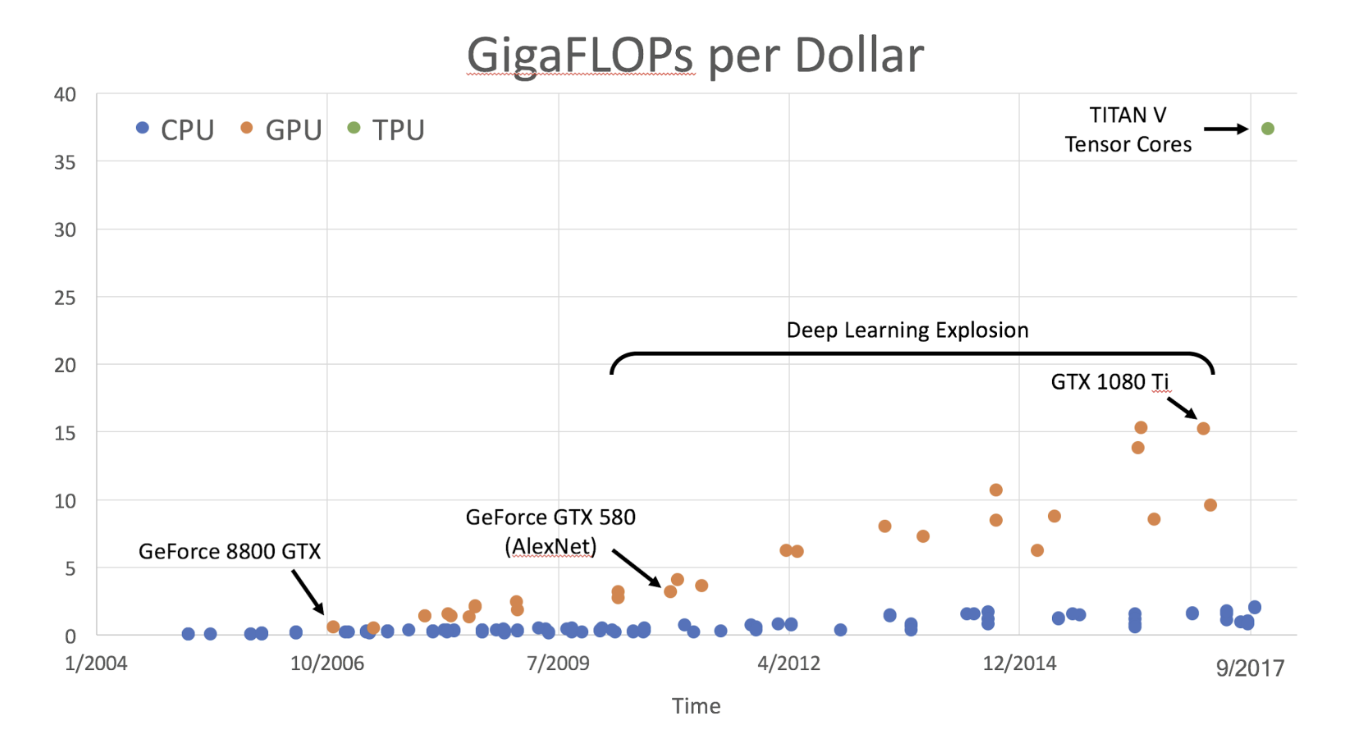
TPU도 등장(?)했다고 볼 수 있다.
저기 오른쪽 상단에 엄청난 성능을 자랑하며 딱 찍혀있는 초록색 점을 보아라.. 엄청난 등장이다 히히
이러한 tensor core를 pytorch에서 활용하는 방법!
- 입력 데이터 유형을 16bit로 전환한 다음 (input_data = input_data.to(torch.float16))
- 올바른 하드웨어가 설치되어 있고 적절한 드라이버가 설치되어 있다면
- pytorch는 연산을 자동으로 tensor core에서 가속화 된다.
Tensor core의 Matrix 연산 예를 보면

output을 4x4의 행렬 덩어리로 만든 다음 그 작은 덩어리를 다른 tensor core 요소에 할당하여 행렬 곱셈을 효과적으로 분산시킬 수 있다.
그렇다면 꼬옥 4x4이어야만 하는가?!
-> 현재는 4x4가 최대치이고, 기본적으로 이것은 하드웨어적으로 4x4행렬을 입력으로 받아 다른 4x4행렬과 함께 사용되어 출력도 동일하게 생성하는 하드웨어이다. 물론 소프트웨어에서 다양한 크기의 행렬곱셈으로 바꿀 수 있지만, tensor core의 하드웨어 적인 부분에서는 4x4 행렬에 최적화 되어있다고 한다.
-> 더하여 2의 제곱꼴이 GPU에서 가장 효율적이다! 컴퓨팅을 낭비하지 않으니까
아래는 GPU를 프로그래밍할 수 있도록 실행 중인 기본 하드웨어 결과이다.

NVIDIA GPU를 프로그래밍하기 위해 CUDA라는 프로그래밍 언어로 다양한 라이브러리들을 최적화 시켜 놓았기 때문에 이를 사용하면 쉽게 프로그래밍이 가능하다. 또한 C 또는 C++의 확장으로 GPU에서 직접 실행되는 코드를 작성할 수 있는 도구이다.
지금까지 우리는 단일 GPU 디바이스에 대해서만 언급했다.
하지만 요즘은 더 많은 사람들이 단일 GPU 디바이스를 넘어서 컴퓨팅 성능을 확장하고자 한다.

위와 같이 실제로 8개의 GPU를 가진 서버를 구매하고, 해당 서버의 모든 GPU계산을 분산시키거나 계층적으로 구성한다.
server -> GPU -> streaming processor -> tensor core
지금까지는 NVIDIA 이야기였고, google은!

google은 딥러닝 연산을 수행하기 위한 자체 전용 하드웨어 장치를 개발해왔는데, 바로 TPU v2이다.
보드 하나당 약 180TFLOPs의 연산 능력을 가지고 있으며 보드 자체에 엄청난 양의 메모리가 탑재되어 있다고 한다.
더하여 matrix multiplication에 특화된 하드웨어이며 NVIDIA의 tensor core와 비슷한 역할을 한다고 한다.

특히 TPU를 단독으로 사용하기보다 여러 개를 assemble하여 사용하는 경우가 대부분인데, 이를 TPU pod이라고 한다고 한다..
위 오른쪽 사진은 64개의 TPU가 모인 것(v2)을 보여주고 있는데 이는 11.5의 PFLOPs 연산능력을 가졌다고 한다.
* Peta : 10^15 !! 참고로 Tera는 10^12 이다. ..
계속 발전해와서 TPU v3가 등장했다.

이는 하나의 칩에서 420 TELOPs의 연산 능력을 가지고 있으며 cloud TPU v3 pod은 이러한 TPU가 256개가 모여있는 것을 말한다.
이러한 TPU를 사용하기 위해서는
우리는 tensorflow를 사용해야만 한다. 하지만! 현재는 torch-xla package를 import해서 쓰면 가능하다고 한다!
다음은 소프트웨어에 대해 알아보자!
- Software

먼저 프레임워크의 전체적인 구도를 볼텐데 오른쪽에 있는 8개가 현세대의 프레임워크라고 볼 수 있다.
이 중에서 pytorch, tensorflow가 가장 초점이 맞춰져있다고 생각하면 된다.
우리가 딥러닝 프레임워크를 사용하기 위해서 알아야 할 점들이 있는데,

- 새로운 아이디어가 있을 때 빠르게 prototyping 하기!
- 이는 딥러닝 프로젝트에서 공통적으로 수행되는 작업에 여러 layer나 기능들을 제공하여 매번 같은 코드를 새로 쓰지 않도록 해야한다는 의미를 가지고 있다고 한다.
- 자동적인 gradient 계산
- 우리가 input에 대해 loss가 나오는 과정을 구도화 시킨 computational graph를 통해 backpropagation 하는 방법들을 6강에서 배웠다. 이러한 과정들이 딥러닝 프레임워크에 적용시켜야한다!
- GPU, TPU 등이 다른 하드웨어 디바이스에서도 효과적으로 작동해야 함.
양대산맥이라고 볼 수 있는 pytorch와 tensorflow 중 PyTorch에 대해서 알아보자. (강연자가 페이스북에서 근무하셧나봐용)
-- PyTorch

현재는 더 높은 버전이 제공되고 있는데, 현시점에서 이전에 비해서 더 많은 것들이 개발되고 수정되었다는 의미를 가진다.
그래서 이전의 것들이 수행이 안될수도 있고 여러가지 에러사항이 있을 수 있다. 버전에 관해 유심히 보고 다룰 필요가 있다!
pytorch : Fundamental Concepts

pytorch는 기본적으로 위와 같은 3가지의 기본적인 컨셉을 가지고 있다.
- Tensor
- python에서 제공되는 numpy array 같은 muilty demention matrix 라고 생각하면되는데, GPU 상에서 돌릴 수 있다! 는 차이점이 있다.
- Autograd
- input과 weight 들 사이에서 이루어지는 여러가지 tensor의 연산들을 computational graph로 만들고, 그러한 것들이 자동으로 이루어지도록 map으로 구현되어 있다.
- Module
- layer와 layer 사이에 FC인지, convolution인지 미리 모듈화해서 만들어놓고, state나 learnable weight를 handling하는 방식으로 되어있다.
Pytorch : Tensors
한 예시로,
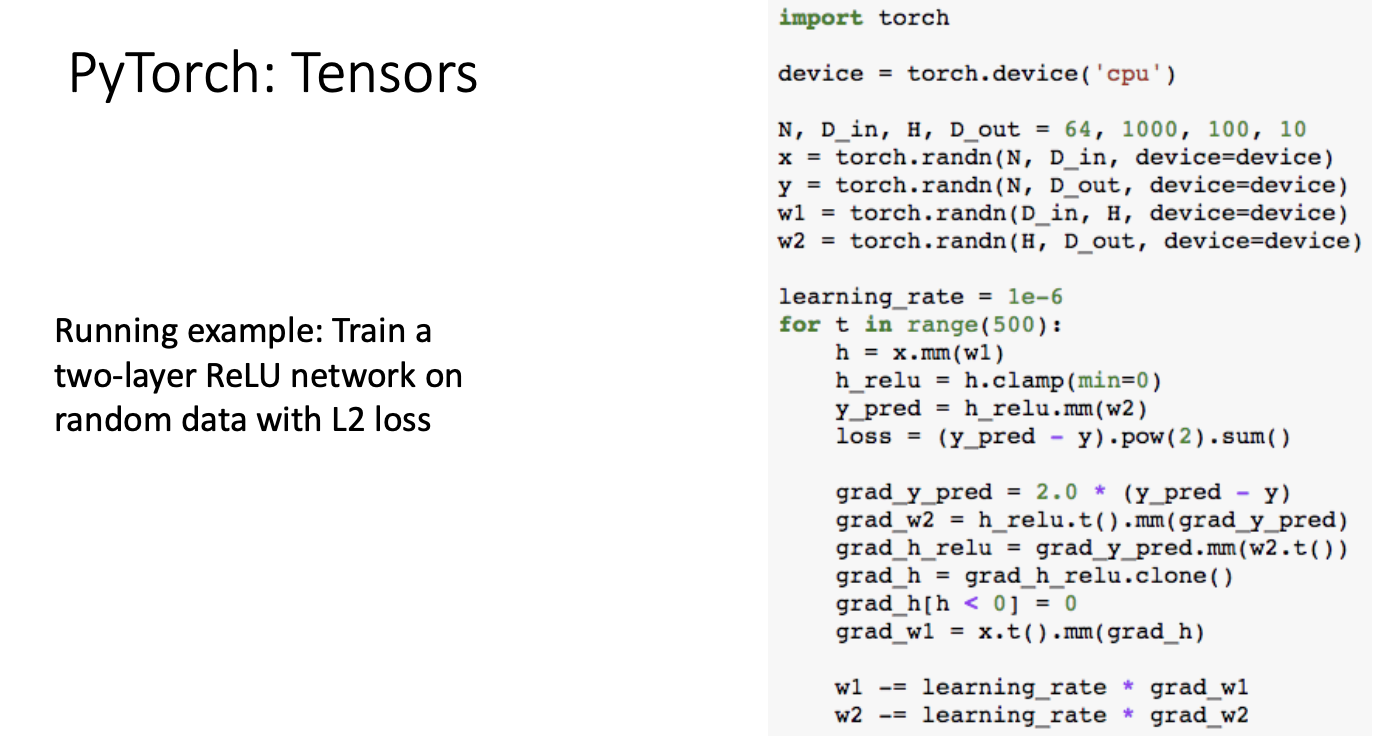
random data로 2개의 layer에 FC network와 L2 loss를 적용하여 train하는 코드는 위와 같은데
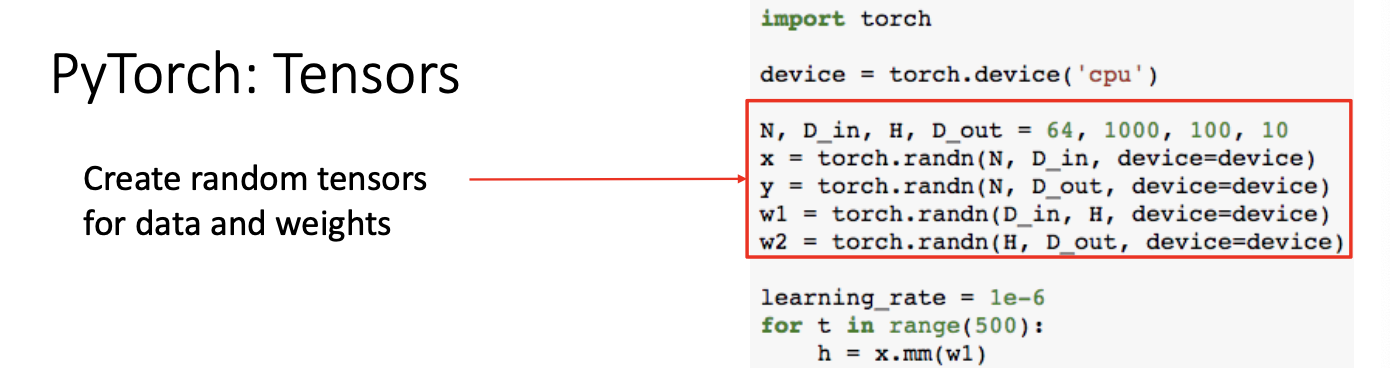
- input : x
- output : y
- weight : w1, w2 이고,
- hidden layer : H
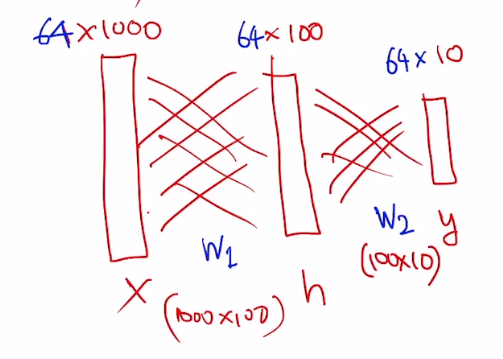
위와 같은 형태로 나타낼 수 있다. 이 모든 것은 matrix로 연산할 수 있으며 그것들이 즉 모두 tensor가 되는 것이다.

forward pass를 통해 prediction과 loss를 계산하는데, 위에서 보았듯 h는 x와 w1의 곱의 형태로 나타낼 수 있으므로 빨간색 상자안에 첫번째 줄을 보면 행렬곱연산을 진행하는 것을 볼 수 있다. 그 다음 relu도 적용해주는 것을 볼 수 있다.

다음은 이제 backward pass를 통해 gradient를 구할 수 있다.
chain rule 에 의해서 down stream gradient를 구해나가는 과정이다.

gradient를 구하면 learning rate 에다가 gradient만큼을 곱해서 learnable parameter인 weight를 업데이트 해주는 과정이다.
이 과정에 GPU를 적용해보면,

위와 같이 torch.device('cuda:0') 라고 쓰면 GPU를 쓰겠다! 라는 의미가 된다.
그렇다면 이제 수동으로 말고 자동으로 gradient를 구할 수 있게 된다.


우리가 tensor를 만들 때 requires_grad=True로 설정해주어 자동화가 가능하게 코드를 작성한다.
Input과 output은 필요없고 learnable parameter인 weight만 적용시켜주면 된다.
그럼 자동으로 pytorch내부에서 computational graph를 만들어주고 그것을 관리해주는 방식이다.
다음 backward를 위해 아래와 같이 코드를 작성해주면,

requries_grad=True가 되어있는 부분만 backward연산이 진행된다.
실제로 내부적으로 어떻게 구현되는지 보자면,
Pytorch : Autograd

최종적으로 위와같은 computational graph를 내부적으로 구현되어 관리할 것이다.
여기서 backward pass를 통해 gradient를 다 계산하고 나면,
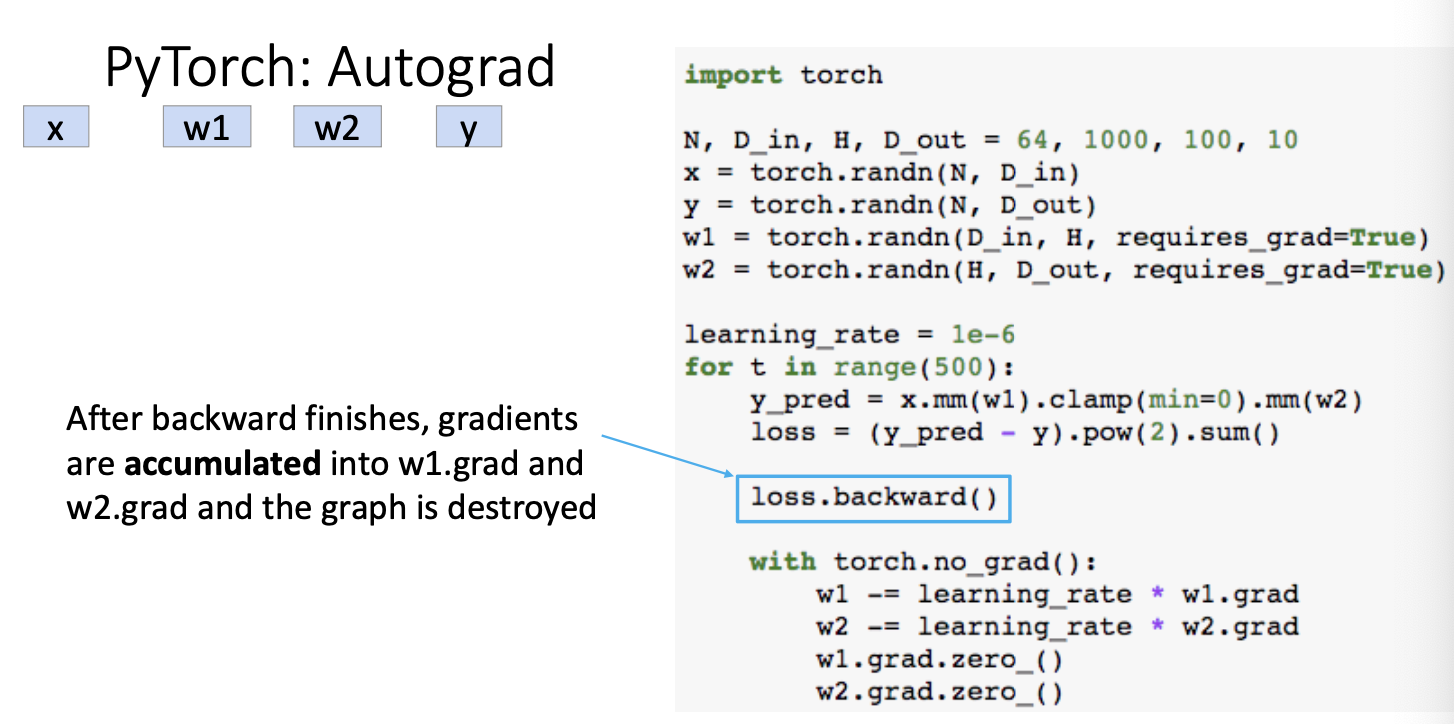
Pytorch의 특징 중 하나인데, computational graph를 다 destroyed를 시킨다.
그 전에 w1.grad와 w2.grad는 다 accumulate 즉, 모으는 개념이다! loss는 다 sum이니까! gradient도 마찬가지!
또 코드 작성시 주의해야할 점이 있다.
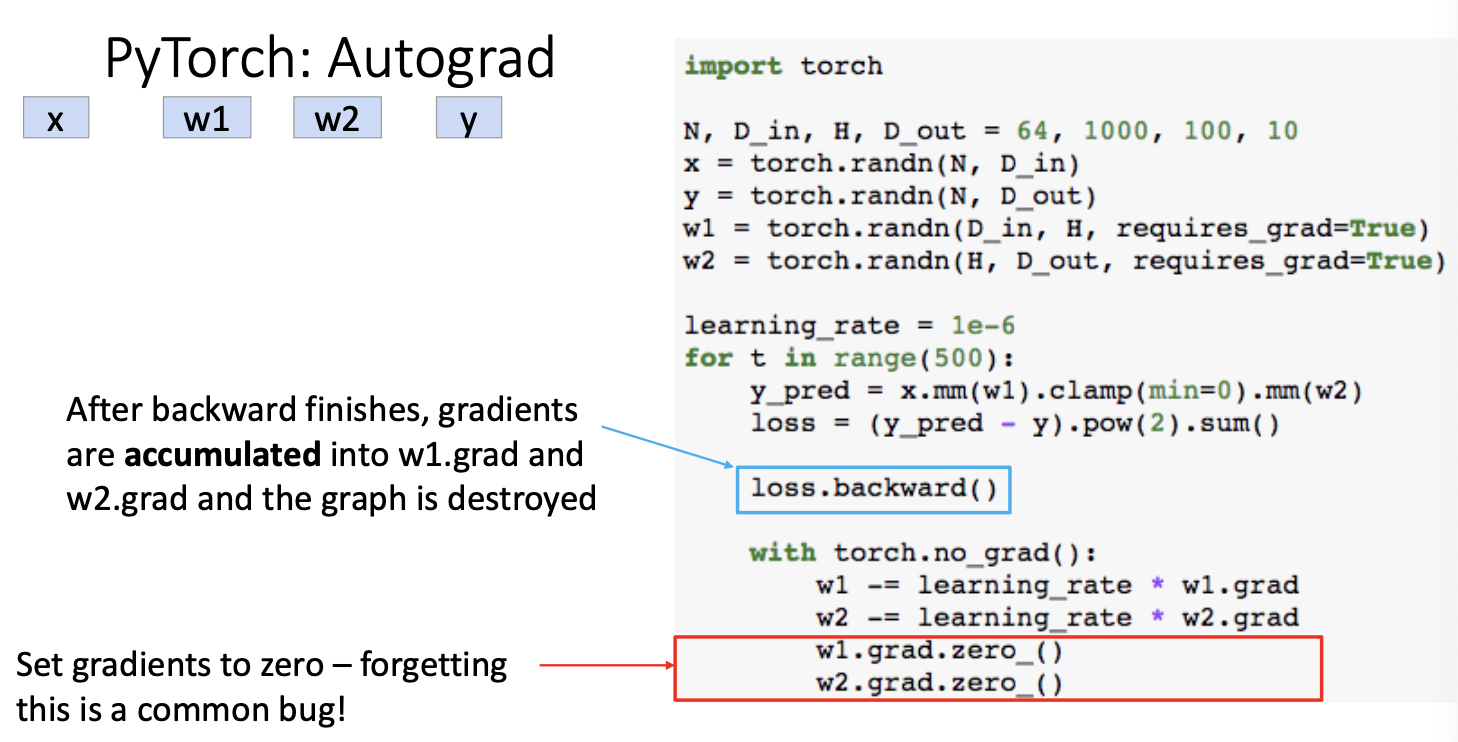
loss.backward()에서 gradient가 accumulated 되기 때문에, 마지막 for문 아래에서 다시 gradient를 0으로 셋팅해주어야 gradient를 새롭게 다시 계산할 수 있다는 점을 인지해야 한다.

그리고 위에서 연산하는 과정은 내부적으로 computational graph가 만들어지는데, w1과 w2를 업데이트 하는 과정은 computational graph에 포함되면 안되므로 with torch.no_grad():라는 코드와 함께 아래 코드들을 작성해야 한다는 점도 주의해야 한다.
Pytorch : New functions
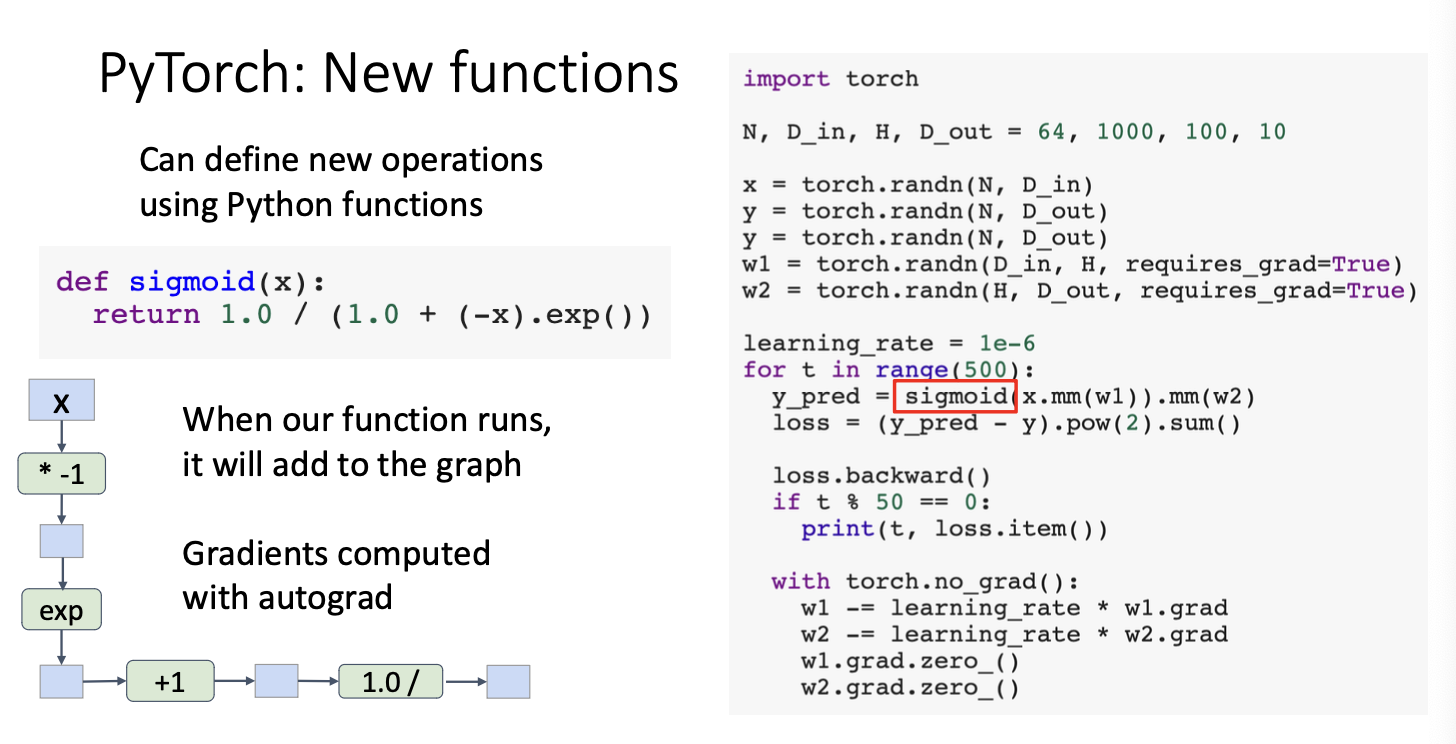
그리고 pytorch는 완전히 python과 연결되어 있기 때문에 python으로 함수를 구현한 뒤 가져다가 써도 문제가 없다.
위에서는 sigmoid func을 구현하였는데, 이 부분 또한 내부적으로 computational graph가 만들어지고 gradient도 업데이트 되는 것을 알 수 있다.
function이 아닌 class단위로 구현한 뒤 사용해도 된다.


따라서 forward와 backward가 다 정의되어있는 class가 있다면 return Sigmoid.apply(x)와 같은 형태로 코드를 작성하여 하나의 노드처럼 생각하고 연산에 적용할 수 있게 된다.
하지만 또.. 이런 경우는 꽤 드물다...

대부분의 경우는 python function으로 구현되어있기 때문에 충분히 그 안에서 활용이 가능하다고 합니당.
다음 pytorch로 neural nets을 들여다봐보자!
Pytorch : nn

model은

Sequential 이라고 하는 class function에 의해서 연속적인 것들을 하나의 model object로 정의한다.
그 모델을

forward 연산에 적용시킬때는 위 코드와 같이 model(x)로 작성해주면 된다.
nn안에 보면

nn.functional이라는 곳에 여러가지 loss들을 미리 정의해두었다. 여기서는 mse loss를 사용하고 있는 것을 볼 수 있다.
forward 연산 후 backward pass를 진행하면 된다.

우리가 위에서 명시적으로 w를 정의하진 않았지만 암시적으로 torch.nn.Linear라고 작성하면서 weight를 내부적으로 정의하였다.
그래서 모든 weight에 대해서 backward 연산을 진행할 수 있다.

weight를 업데이트 해주는 과정인데, 여기서도 model.parameters()를 작성하면 내부적으로 정의했던 weight들이 불려온다.
그리고 pytorch에서는 여러가지 optimizer가 정의되어 있는데,
Pytorch : optim

torch에서 optim이라는 패키지 안에 위에서는 Adam을 불러와 사용 중인 것을 볼 수 있겠다.

따라서 위에서 봤던 작업들을 optimizer를 활용하여 업데이트하고, 0으로 셋팅하는 과정을 간단하게 작성할 수 있다.
이런것들을 조금 더 효과적으로 사용할 수 있게 한 것이 위에서 봤던 세번째 특징인 Module 이다.

Module은 neural networks의 하나의 layer 즉, input이 있고 output이 있으며 그 사이에 weight가 있는 layer 한 세트를 말한다.
module 안에 module이 있을 수도 있으며 우리가 이미 알고있는 모듈들을 새로 custom하여 사용하는 경우도 있다.
예를 들면

위와 같은 TwoLayerNet이라는 모듈이 있다. 앞에서 보았던 2개의 layer가 있는 구조인데 self.linear1, 2도 또한 TwoLayerNet안에 있는 또 다른 작은 모듈로 바라볼 수 있는 것이다.
이러한 모듈을 define하기 위해서는
1) initialization

2) forward pass define

-> hidden layer와 output을 계산하는 과정
** backward는 필요없음! -> autograd가 알아서 해 줄거기 때문에!
아래와 같이

모듈을 graph로 나타낼 수 있다.
위의 한 덩어리가 첫번째 parallelBlock, 중간 덩어리가 두번째 parallelblock, 마지막이 linear라고 보면된다.
Pytorch : DataLoaders

그리고 또한 pytorch 에서는 위와 같이 데이터를 로딩하고 mini batch를 생성하고, 데이터를 shuffle 하는 등 여러가지 기능을 제공해주는 dataloader 메커니즘을 제공하고 있다.
더하여
Pytorch : pretrained Models
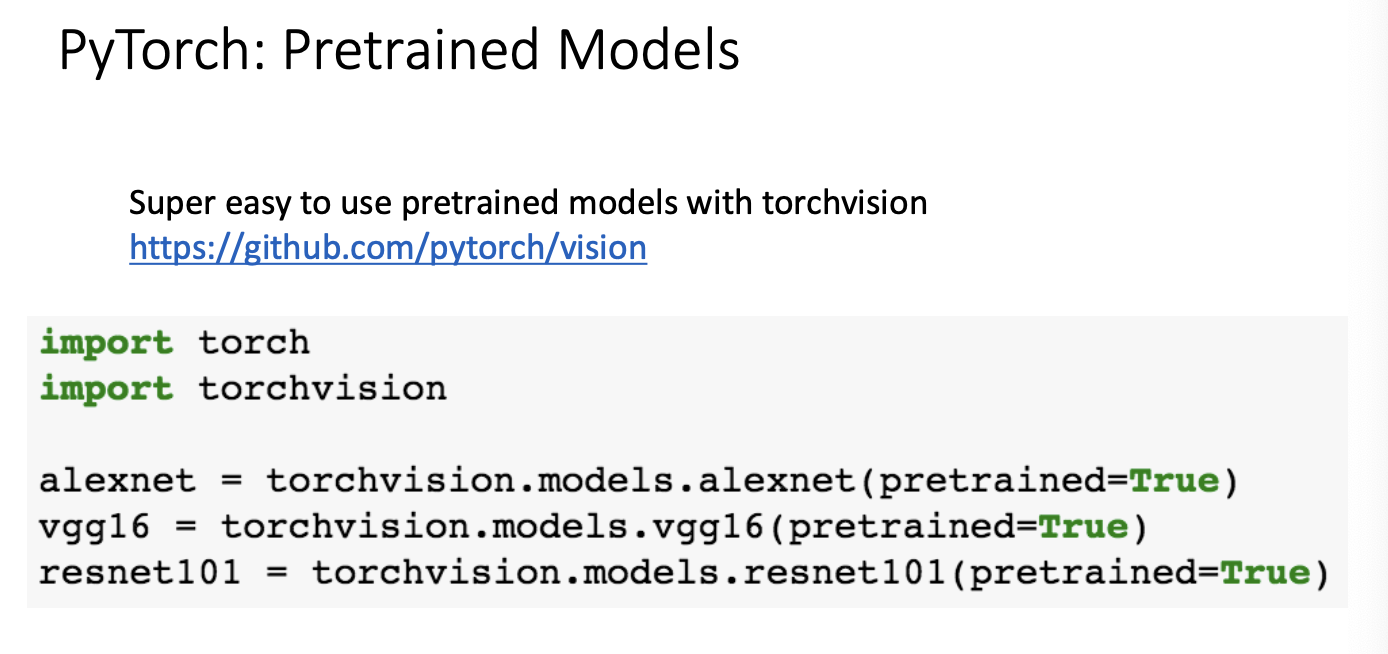
위와같이 코드를 작성하면 사전에 훈련된 모델들을 제공해주기도 한다.
pytorch : Dynamic Computation Graph
앞선 예제를 설명하면서 for문을 돌 때마다 forward pass과정에서 computational graph를 그리고, backward pass를 통해 gradient를 구하면 다시 그래프를 지우고, 다음 epoch에서 위 과정을 반복하는 구조를 설명하였다.
위와 같은 과정을 'Dynamic Computation Graph'라고 한다.
근데 이렇게 비효율적인 과정을 굳이 왜 할까?
Pytorch : Dynamic Computation Graphs

위 코드와 같이 이전의 loss를 weight 업데이트시 사용해야하는 경우가 있다. 반복문 안에 조건문이 들어가 control flow가 모델에 포함되어버리면 dynamic computation graph가 유용하게 사용될 수 있기 때문이다.
위 코드를 자세히 보면 1epoch에서 w2a가 가중치로 사용되었지만 2epoch에서는 조건문에 따라 w1a, w2b가 결정되기 때문에 매 반복문마다 computation graph를 새로 작성하는 것이 빛을 발하는 것이다.
하지만! 비효율적일때도 분명있다. -> 이 부분을 해결해보자면
Alternative : Static Computation Graph

위 코드와 같이 build_graph() 하면 딱 graph를 만들어준다.
다음은 run_graph를 해서 만들어진 그래프 안에서만 반복문이 실행되는 graph이다.
pytorch 역시 위와 같은 정적 그래프를 만들 수 있는데, 그것을 JIT라고 한다.
Pytorch : Static Graphs with JIT

위와 같이 python function으로 model을 define 하고,

torch.jit.script(model)을 작성해주면 이것을 컴파일하여 그래프를 만들고, 만들어진 그래프를 활용할 수 있다.

조건문이 있는 경우도 condition load를 넣어 처리할 수 있게 되어있다고 한다.

loss를 계산할 때는 연산에 필요한 다른 것들과 이전 loss인 prev_loss를 가져와 연산에 이용하는 것을 볼 수 있다.
그래서 static graph를 사용하기 위해서는

위와 같이 model을 define 하기 전에 @torch.jit.script와 같은 annotation을 붙여서
나 다이나믹이 아닌 static graph를 쓸거야! 라고 알려주어야 한다.
annotation을 붙이지 않으면 자동으로 dynamic graph를 사용하게 된다.
Static VS Dynamic Graph : Optimization, Serialization, Debugging

Optimization에 있어서는 static graph가 이점이다.
코드를 작성할 때 layer를 따로따로 작성하였더라도 Conv, ReLU layer와 같이 서로 합칠 수 있는 것들은 알아서 척척 합쳐주는 등의 최적화가 이루어질 수 있기 때문이다. -> fused operation이 가능!

Serialization 즉, 직렬화에서도 static graph가 더 좋다.
직렬화는 메모리를 디스크에 저장하거나 또는 통신에 사용할 수 있는 형식으로 변환하는 것이라고 할 수 있다.
여기서 static graph는 모델을 구현하는 코드를 python으로 작성한 후 C++와 같은 다른 언어로도 해당 그래프에 접근할 수 있게 되어 비교적 속도가 빠른 C++로 사용할 수 있다는 장점을 얻게된다.
but, 다른 언어를 사용하게 된다면 디버깅이 힘들다는 단점도 생길 수 있다는 점! 인지해야한다.

Debugging에서는 Dynamic graph가 이점이다.
중간 중간 어떤 식으로 진행되는지 쉽게 확인할 수 있기 때문! 에 아주 직관적인 장점이라고 볼 수 있겠다.


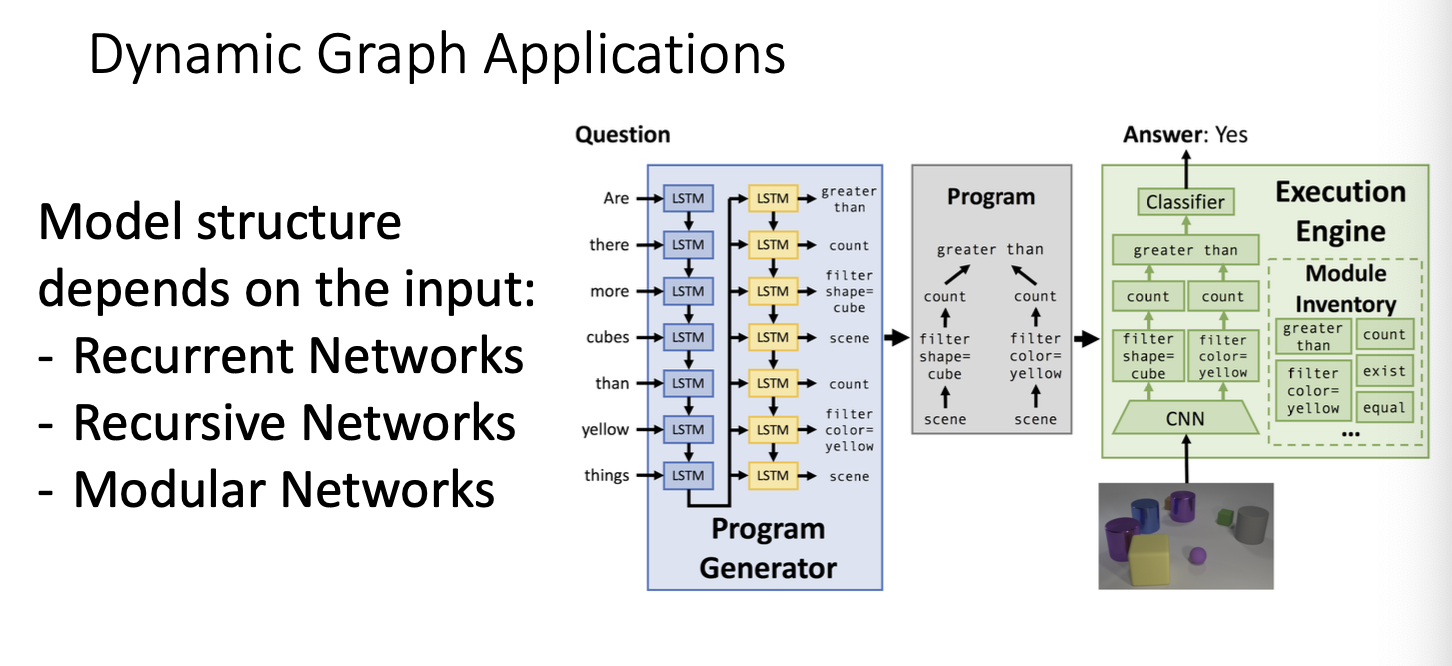
또한 dynamic graph의 경우 input에 따라서 model structure가 여러개가 나올 수 있다는 특징에서 또 강점을 보일 수 있다.
다음 TensorFlow를 알아보자!
--TensorFlow

tensorflow 1.0과 2.0을 비교하자면,
| TensorFlow 1.0 | TensorFlow 2.0 |
| default가 static graph | default가 dynamic graph |
| 디버깅이 비교적 복잡 | keras로 표준화 되어있음. |
| API가 깔끔하지 않음 |
Pytorch vs Tensorflow

오늘의 썸머리!


사진으로 대체 가능할 것 같당.
와 오늘도 하루가 지나기 전에(?) 완료했어!
짱 뿌듯하지만 새벽 두 시당
졸리고 추워
집 가기 귀찮아 순간이동 절실하다
가서 웰컴투 삼달리 마지막화 남은 거 봐야지
이거 보느라 4일 내내 울고 잇잔아
어쩌라고 빨리 짐 싸
웅!
'EECS 498-007' 카테고리의 다른 글
| [EECS 498-007] Lecture 12. Recurrent Neural Networks (3) | 2024.02.03 |
|---|---|
| [EECS 498-007] Lecture 10. Training Neural Networks I (2) | 2024.01.29 |
| [EECS 498-007] Lecture 08. CNN Architectures (2) | 2024.01.24 |
| [EECS 498-007] Lecture 06. Backpropagation (1) | 2024.01.21 |
| [EECS 498-007] Lecture 04강 Optimization (1) | 2024.01.11 |