오늘은 오디!
오브젝트 디텍션이당
어쩌다보니 광양이긴한데..
이사하고 나니까 온 몸이 아푸긴한데
화이팅!

지금까지 우리는 기본적으로 이미지 분류 문제들을 위주로 다루었다.
input image를 CNN 모델에 넣어 이미지가 고양이인지, 차인지, 강아지인지 등과 같은 카테고리 라벨을 얻었다.
하지만 컴퓨터비전 분야에는 더 다양한 task가 많은데,
이번 강의에서는 이미지상 객체의 공간적 존재 여부를 식별하는 다양한 방법에 대해 알아볼 것이다.
고전적인 image classfication task처럼 각 이미지의 픽셀별로 테고리 라벨을 붙이는 것이 아닌 주어진 이미지에 대한 카테고리 라벨을 구하는 것이다.
그 중에서도 Object Detection, 객체 탐지라는 작업에 대해 다루어 볼 것이다. 이는 컴퓨터비전의 수 많은 응용 분야에서 핵심이 된다고 한다.
Object Detection
- Input : sigle RGB image
- Output : 검출한 객체들의 집합
- 검출된 객체의 카테고리
- 바운딩 박스로 이루어진 위치정보 (중앙점 x, y와 폭과 높이 w, h)

객체 검출에서 다루어야할 문제
- Multiple outputs
- 이미지 분류의 경우 하나의 이미지에 대해 하나의 분류 결과를 냈으면 되었는데, 이미지에서 검출된 객체 전체의 분류 결과를 만들어내야 하는 것이다. 즉 모델을 만들 때 고정된 크기의 출력이 아닌 가변 크기의 출력을 내도록 설계해야 한다.
- Multiple types of output
- output의 타입이 다르다는 것이다. 하나는 카테고리 라벨, 다른 하나는 바운딩 박스이다. 따라서 바운딩 박스를 구할 수 있도록 하는 과정이 필요하다.
- Large images
- 마지막으로는 계산 비용 문제인데, 상대적으로 고해상도 이미지에서의 처리가 필요하다. 이미지 분류의 경우 저해상도 이미지로도 충분하였지만 객체 탐지에서는 여러 객체들을 식별해야 하므로, 탐지를 할 만큼의 이미지의 공간적 크기(해상도)가 필요한 것이다. 따라서 학습 시간이 오래걸리고, 계산 비용 문제가 따른다.
하지만 Object detection은 매우 유용한 task로 많은 시스템에서 사용되곤 한다. 예를 들면 자율주행 자동차인데, 자율 주행차의 비전시스템을 만든다고 하면 차 주위에 무엇이 있는제 알아야 한다. 즉 단일 카테고리가 아닌 전체 객체들을 구해야 한다.
먼저 이미지의 여러 객체가 아닌 단일 객체를 찾는 경우로 조금 단순하게 살펴보자.

이 경우에는 단순하게 표현할 수 있는데, 왼쪽에 이미지가 있고 특정 신경망 아키텍처에 넣으면 이미지의 표현 벡터가 나오게 된다.
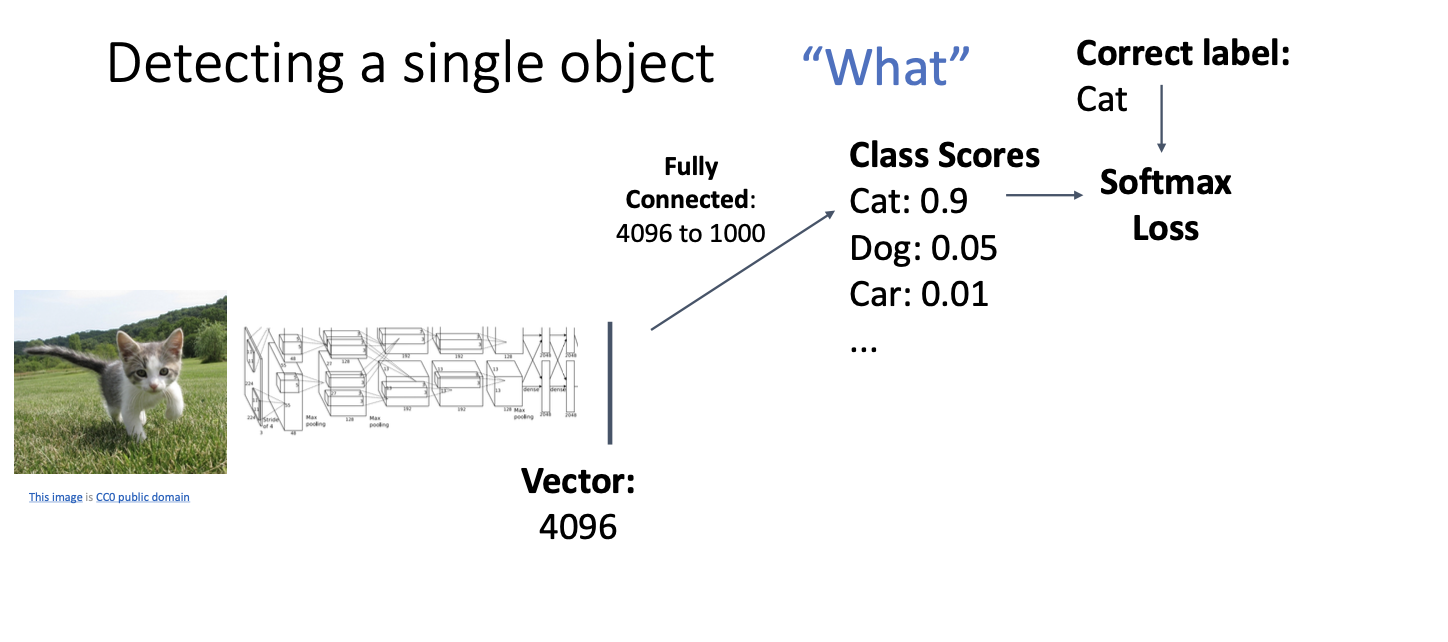
나온 벡터를 활용할 수 있는 것들에는 위와 같은데, 이전에 봤던 것과 같은 이미지 분류에 사용할 수 있다.
카테고리별 score를 구하고, softmax loss를 통해 올바른 카테고리로 분류될 수 있게 확률적 값으로 바꾸어 준다.
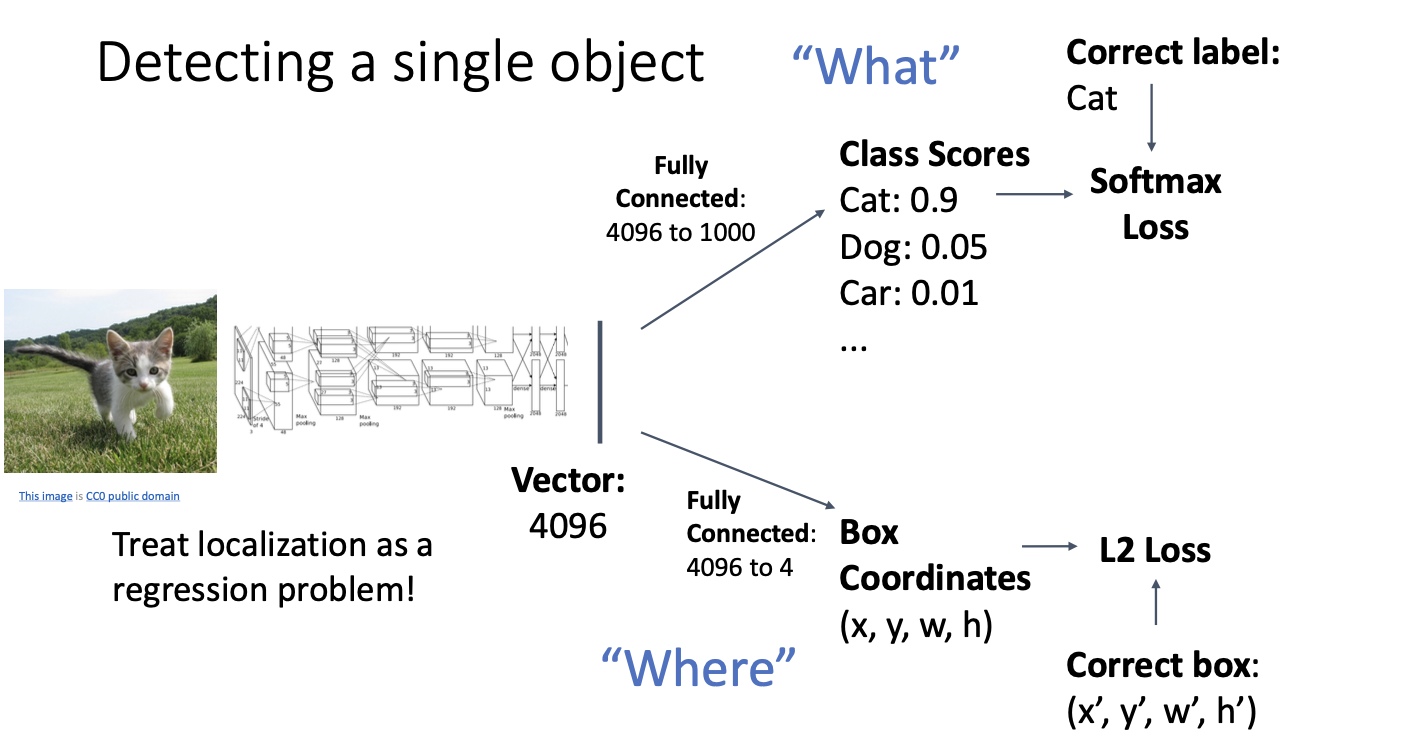
다음 두번째 활용으로는 똑같은 표현 벡터가 들어가지만 4개의 출력을 같는 fully-connected layer를 갖는 것을 볼 수 있다.
이 4개의 수는 bouding box의 좌표계 값들인데, L2와 같은 loss를 사용하여 학습할 수 있다. 즉, 실제 바운딩 박스의 좌표계값과 예측한 바운딩 박스의 좌표계 값의 차이로 학습을 하는 것이다.
여기서 문제점이 발생하는데!
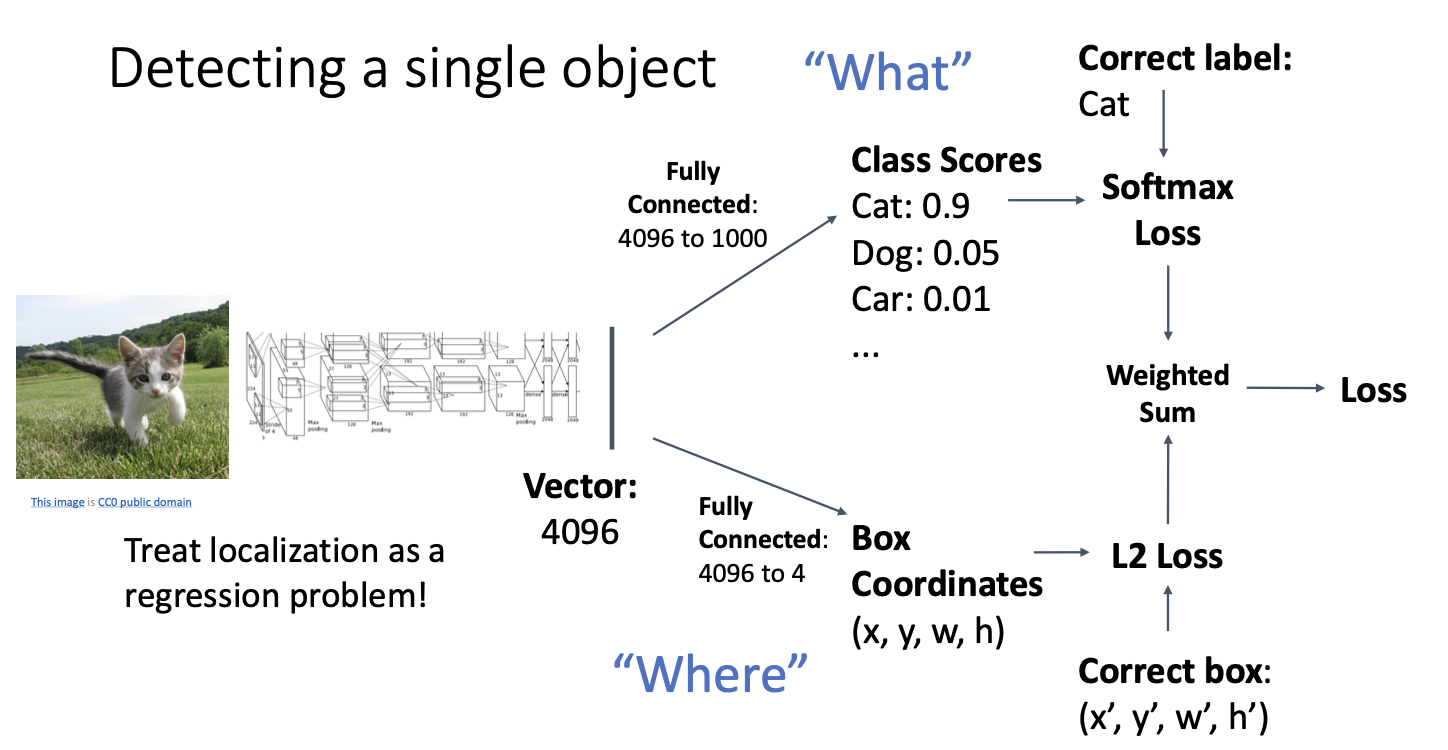
두가지의 종류가 다른 loss를 사용한다는 점이다.
2개의 출력을 내는데, 하나는 라벨 카테고리, 다른 하나는 바운딩 박스의 위치이므로 각 다른 비용함수를 사용해야하는 것이기 때문이다.
이 두가지를 합친 Loss를 구할 수도 있겠지만 gradient desent를 계산하기 위해서는 단일 스칼라 값이 나와야 한다.
그래서 우리는 두 개 이상의 loss를 처리하는 방법을 알아야 한다.
해결방법은 서로 다른 loss들을 weighted sum을 하여 최종 loss를 구하는 것이다.
weighted sum을 구하는 이유는 softmax loss와 L2 loss 사이의 중요도를 서로 압도하지(?) 않도록 미세 조정을 해야하기 때문이다.
이러한 loss를 Multitask Loss! 라고 한다.
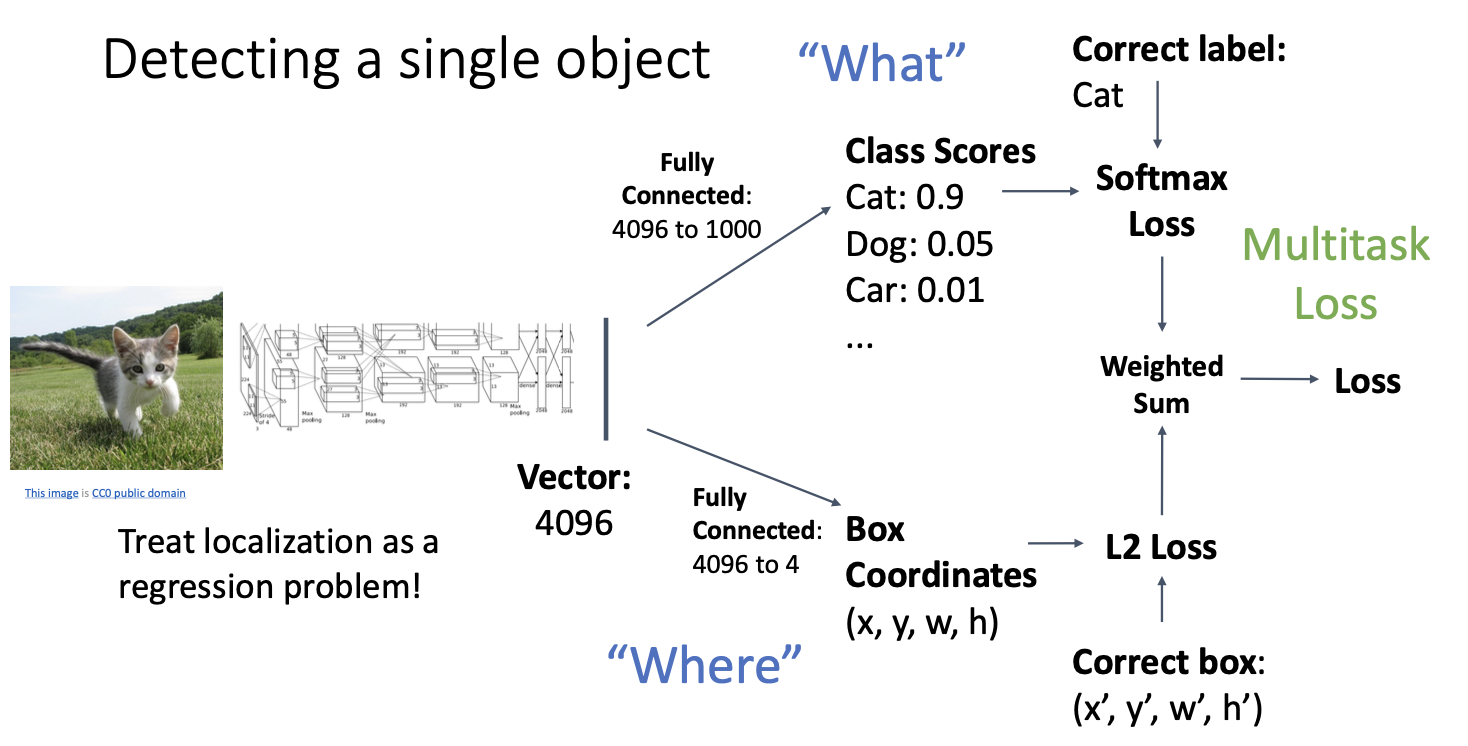
이러한 Multitask loss는 하나의 신경망이 여러개를 학습해야 하는 경우에 사용한다.
그래서 하나의 loss뿐만 아니라 다른 예측할 loss도 추가하고 이들의 가중 합을 구함으로써 신경망이 여러 개의 출력 결과를 학습할 수 있도록 만든다. 끝에는 단일한 loss로 만들어 낸다.
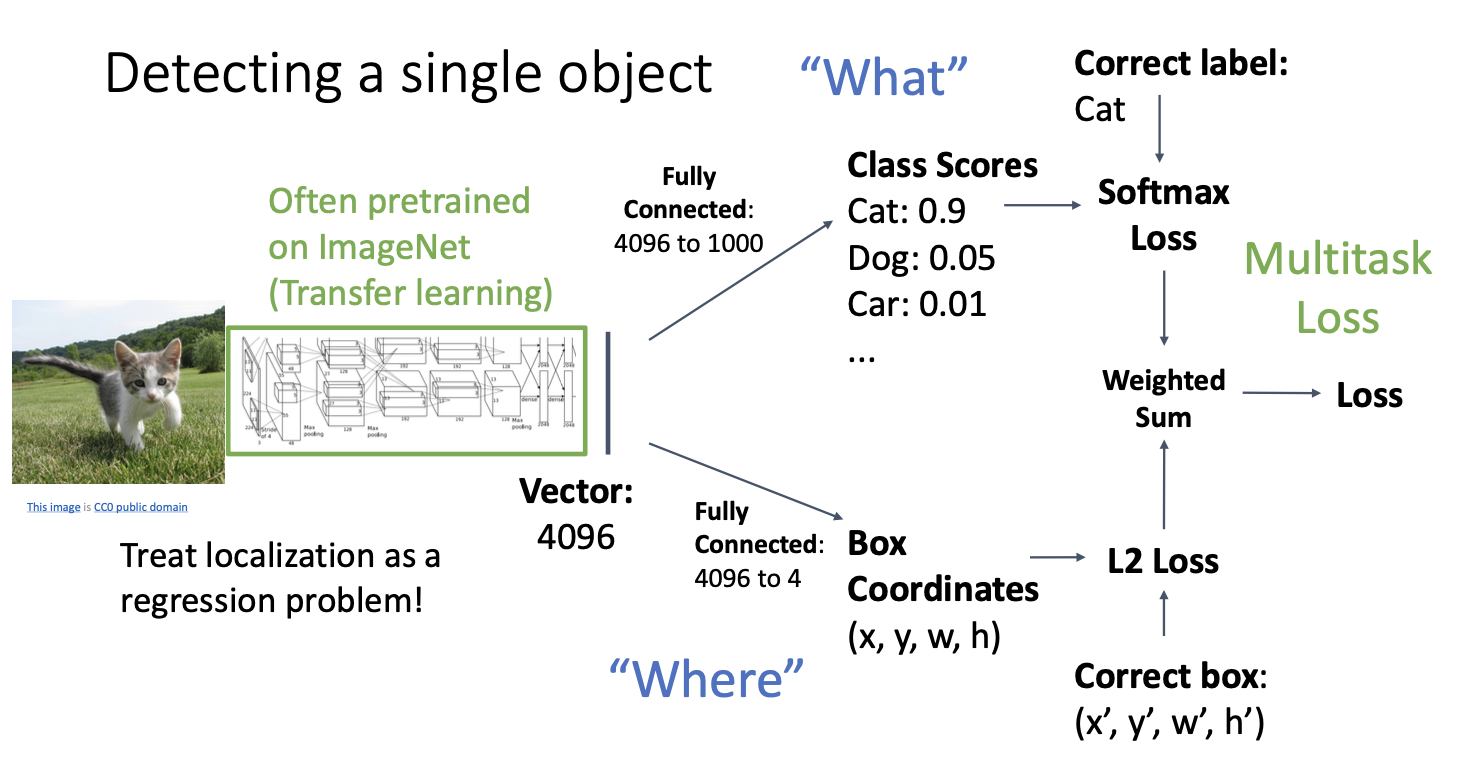
이를 실제로 사용하기 위해선 backbone network, 즉 CNN은 이미지 넷 분류를 위해 사전 훈련 상태로 사용되며, 그 다음에는 전체 네트워크를 multitask loss 위치 추정 문제로 미세조정을 할 수 있다.
하지만 이는 객체 탐지 문제에서는 바보같은 접근 방식이다. 상대적으로 잘 동작하지만 이미지에서 하나의 객체만 탐지하는 경우에 사용되는 방식이기 때문이다! (여러가지를 탐지해내야 해 !! 우리는!!)
따라서
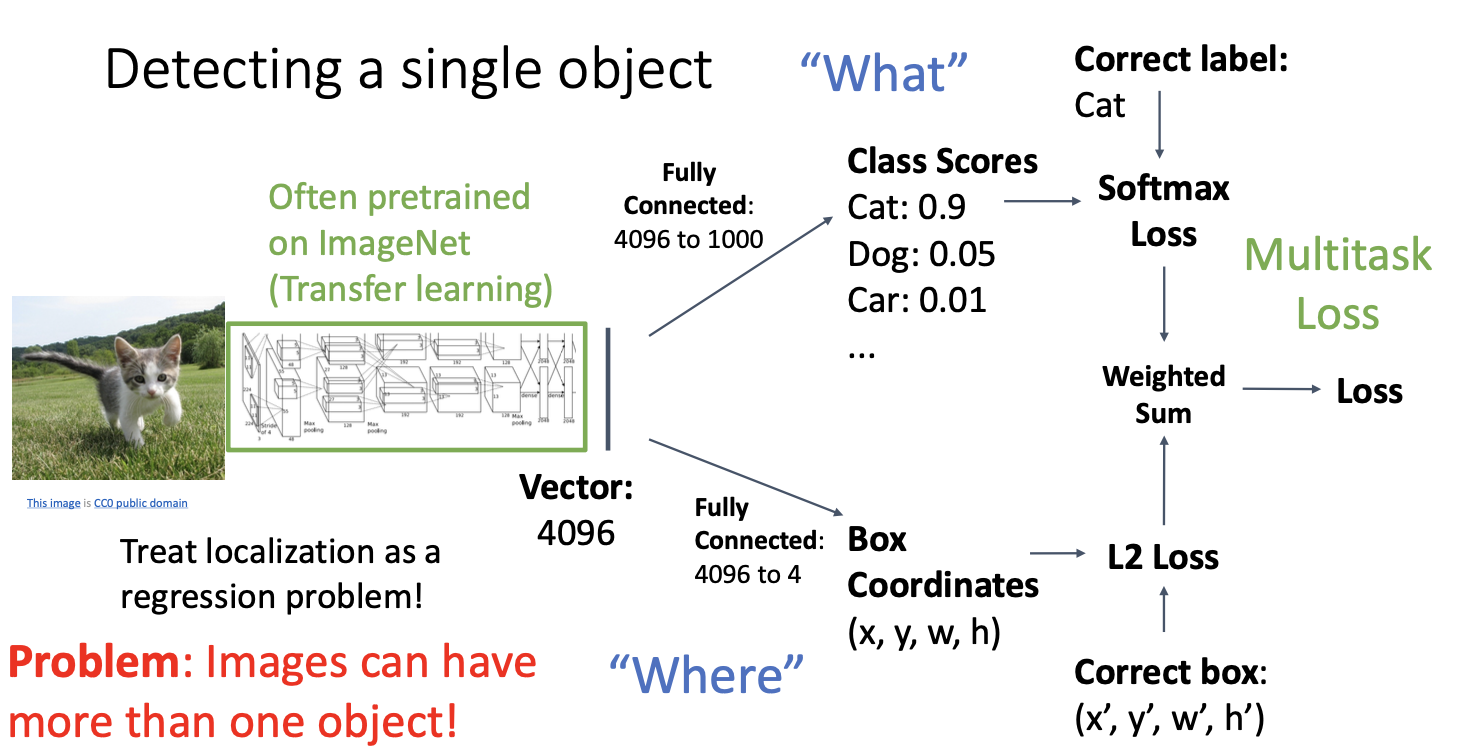
실제 이미지에서는 탐지할 객체가 여러개이므로 일반적 용도로 사용하는데에 적합하지 않아 문제가 된다.
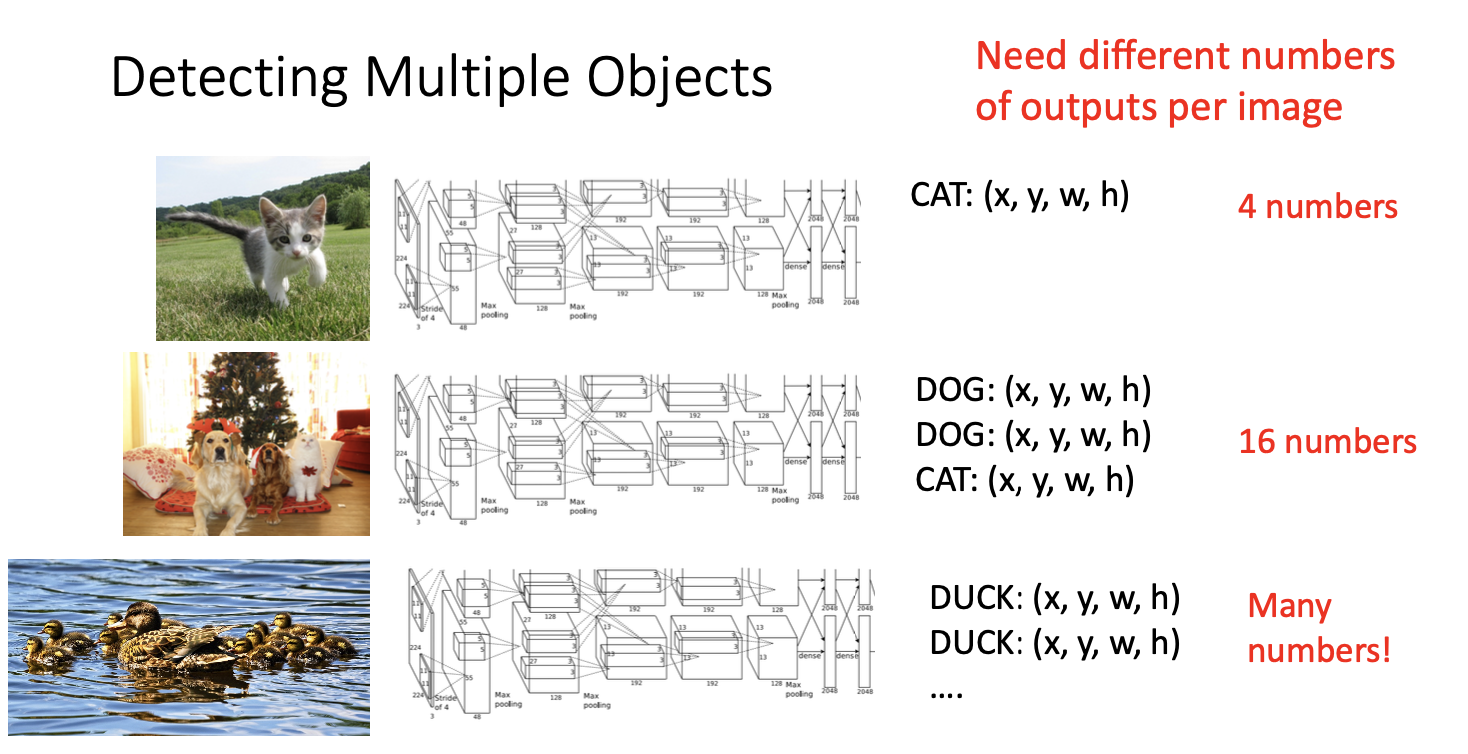
일반적인 이미지의 경우 탐지해야할 다양한 개수의 객체들을 가지고 있다.
첫번째 고양이 이미지의 경우 한 객체만 탐지하여 고양이의 바운딩 박스에 대한 4개의 수를 추정해내면 되지만,
두번째 이미지의 경우 3개의 객체를 탐지해내야 한다. 2개의 강아지와 1개의 고양이로 3 x 4 = 12개의 수를 추정해야 한다. (slide는 오타)
세번째 이미지의 경우 아주 많은 오리들이 있다. 우리의 네트워크는 이 모든 오리들을 탐지해내야 하므로 아주 많은 수의 결과를 추정해야 한다.
따라서 우리의 모델은 다양한 개수의 객체들을 출력 해낼 수 있는 메커니즘이 필요하다.
Sliding Window
sliding window는 상대적으로 쉬운 방법이다.

이 아이디어는 CNN을 사용하여 분류를 사용하되, 분류를 위해 사용되는 CNN은 input image의 window 또는 sub window를 카테고리화 할 수 있는 훈련을 하는 것이다. 각 sub-window에 대해 이를 적용하면 해당 window에 대한 카테고리가 출력되며, 여러 카테고리를 감지하려면 실제로 c가지 카테고리에 대한 결정을 출력하게 된다. 여기서는 특별한 background window에 대한 출력이 추가되어 c+1의 출력이 나타나게 된다.
따라서 기본적으로 객체 탐지의 문제를 이미지 분류의 문제로 축소시키는 것이다.
그 다음 CNN을 입력 이미지의 다양한 영역에 적용하면 각 영역에 대해 해당 분류 CNN이 개인지! 고양이인지! 배경의 영역인지 알려주는 것이다.



위와 같이 개면 개! 고양이면 고양이! 로 바운딩 박스 안에 객체에 따라 분류하는것을 볼 수 있다.
여기서 의문이 들 수 있는데,

가능한 bounding box의 개수는 얼마나 될까?
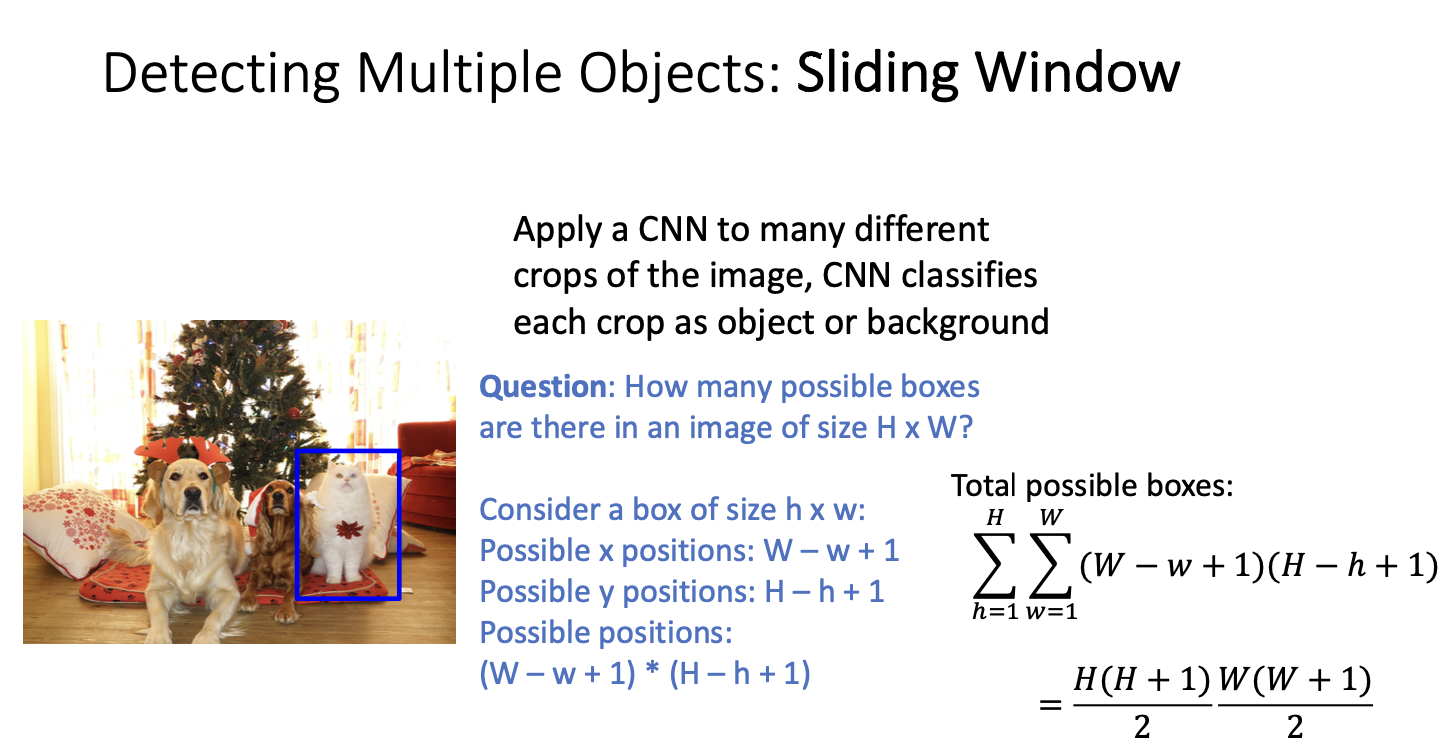
이미지 크기가 h x w인 경우, 가능한 바운딩 박스의 개수는 많을 것이다.
만약 입력 이미지의 크기가 H x W 이고, 박스의 크기가 h x w 라고 가정해보자. 이 상자를 놓을 수 있는 위치는 x : W - w + 1 , y : H - h + 1 라고 생각할 수 있겠다. 이 상자를 놓을 수 있는 위치의 수는 (W - w + 1) x (H - h + 1)이다.
하지만 여기서 우리는 고정된 크기의 박스만 생각하면 안된다. 고정된 크기의 상자뿐만 아니라 가로세로 비율을 갖는 모든 상자를 고려했을 때 위와 같은 이차식 형태의 수들이 존재한다.
이것은 이미지의 픽셀 수의 제곱에 의존하는, 정확히는 이미지의 픽셀 수의 제곱에 비례하는 네제곱 표현에 의존하게 된다.
예를 들어 800 x 600 이미지가 있다면 약 5800만 개의 다른 bounding box를 고려해야한다. 만약 우리가 이 상황에서 sliding window를 사용한다면 완전히 현실적이지 않을! 것이다. 5800만 번의 CNN forward pass를 하나의 이미지에 대해 실행하는 것은 computing 적으로 완전히! 불가능하기 때문이다.
** non-maximum suppression
그래서 우리는 다른 접근 방식이 필요해 !!!
Region Proposal

여기서 아이디어는 이미지의 모든 가능한 영역에서 탐지를 할 수 없다면 외부 알고리즘이 이미지의 후보 영역 집합을 생성할 수 있다는 것이다. 후보 영역들은 상대적으로 작은 sub-region이지만 이미지에서 객체를 높은 확률을 가지고 있다고 한다.
몇년 전 여러 논문에서 다양한 메커니즘을 제안했는데, 이러한 방법을 region proposals라고 부른다.
입력 이미지에 이미지 프로세싱을 거친 후, 이미지 blob과 같은 영역이나 edge영역이나 다른 row-revel 이미지 처리 기법으로 높은 확률로 객체를 가졌을만한 영역을 찾아내는 것이다
여기서 궁금했던 점!
row-level image가 뭐야? -> 코 눈 이런건가
이런 것들 중에서 유명한 방법중 하나는 selective search가 있다. 이는 cpu로도 돌릴 수 있는데, 이미지당 2000개의 region을 몇 초만에 알려준다고 한다. 이 2000개의 proposal 영역들은 우리가 높은 확률로 있다고 보고 주의를 기울일만한 객체들을 가지고 있는 것이다. 이러한 것은 neural network를 이용해서 실제 사용가능한 객체 탐지로 학습시킬 수 있다.
이를 학습시키는 매우 간단한 방법이 있는데,
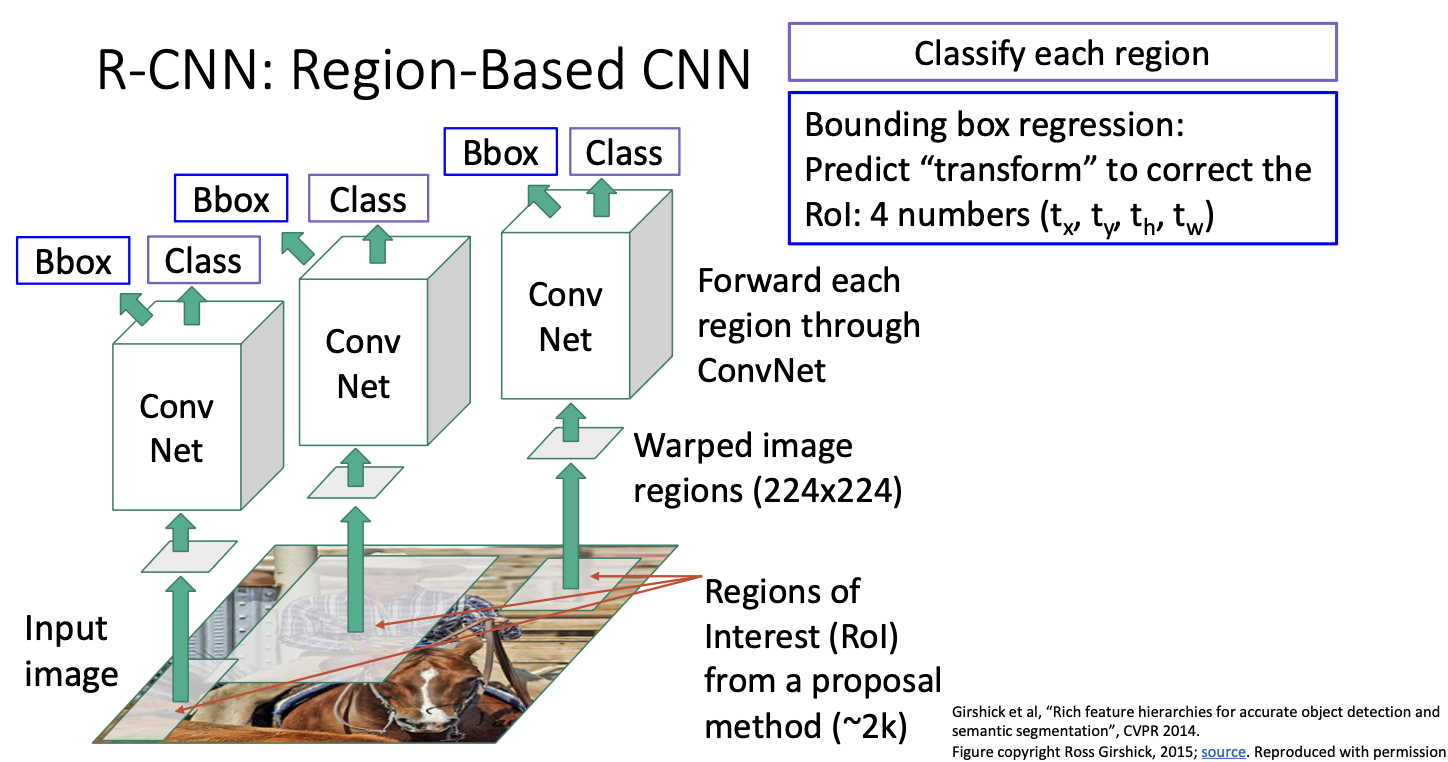
RCNN : Region-based Convolutional Neural Network

객체 탐지를 위한 region 기반의 CNN 시스템이다.
먼저 input image를 가져와 selective search와 같은 region proposal 방법을 실행한다.

그럼 이미지 내에서 약 2000가의 후보 영역 제안을 생성해 주는데, (사진에선 3개만 표시)
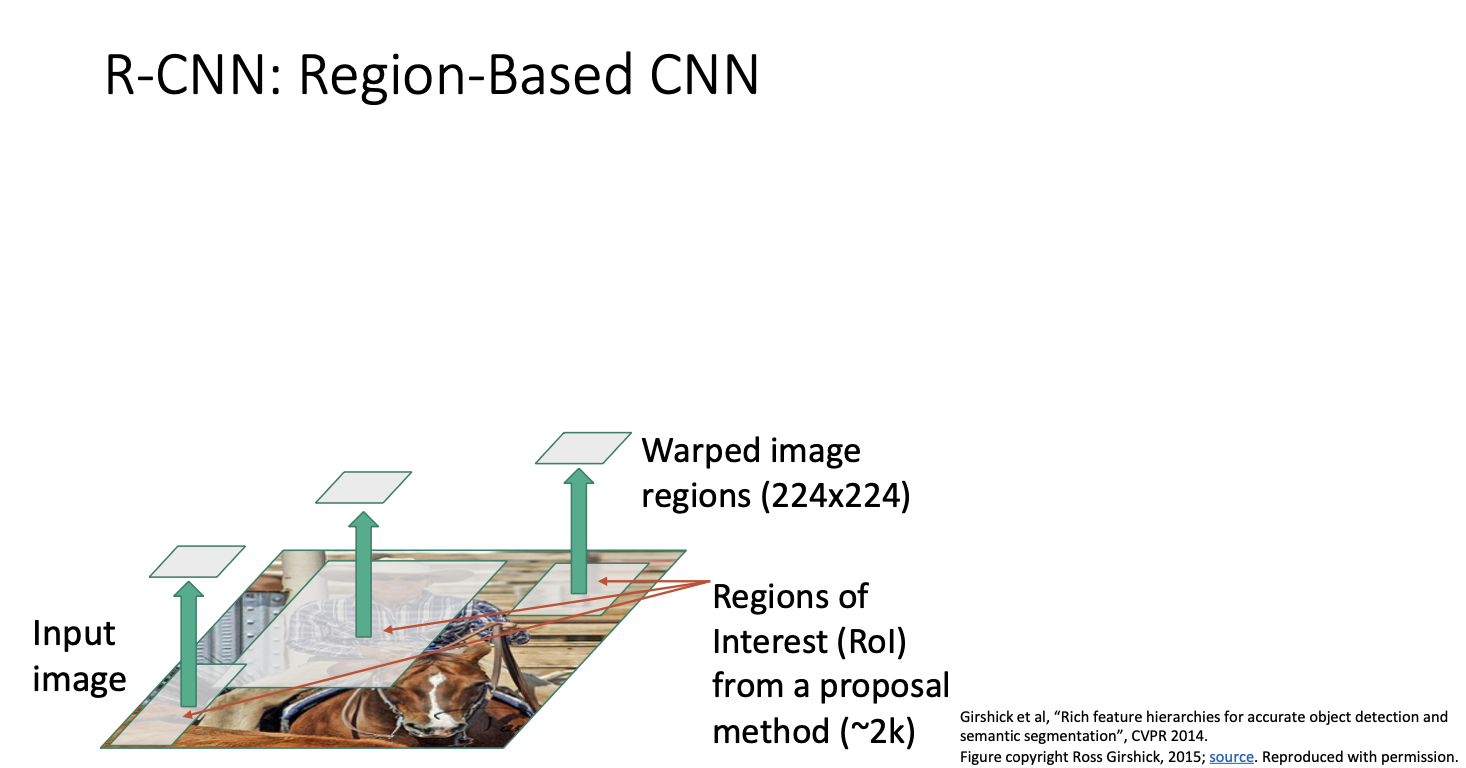
각 후보 이미지 영역은 이미지 내에서 다양한 크기와 가로세로 비율을 가질 것이다. 따라서 각 이미지 영역에 대해 해당 영역을 크기가 224 x 224 정도로 고정 크기를 변형시킨다.

그 후 각 변형된 이미지에 대해 독립적으로 Conv Net을 적용시킨다.
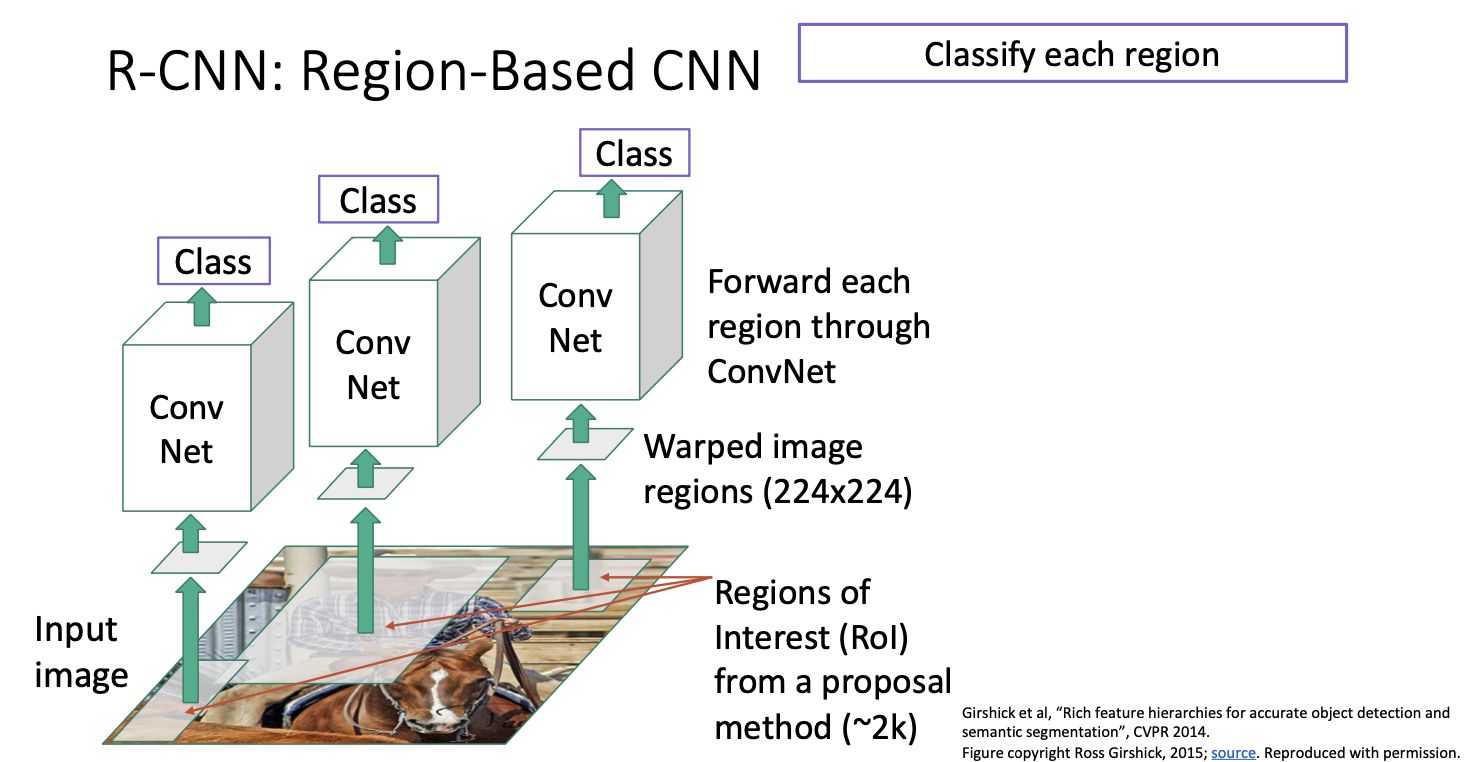
그 다음 각 분류 score를 출력하게 된다. 이 c+1개의 분류 score가 배경인지 혹은 배경이 아닌 다른 무엇인지 알려주게 되는 것이다.
근데 여기서 문제가 있는데! 선택적 탐색으로 얻은 proposal region들이 실제로 우리가 탐지하고 싶은 것과 일치하지 않을 수 있다는 점이다. 여기서 구하는 전체 bouding box들을 구하는 메커니즘은 selective search를 사용하기 때문에 박스를 구하는데에 있어서 학습 과정이 존재하지 않는 것이다.
그렇다면! 어떻게 극복할까!!

multitask loss와 같은 방법을 사용해서 CNN이 추가 정보를 내도록 바꾸어 예측한 bouding box가 실제로 우리가 원하는 박스를 출력하도록 하는 변환을 추가하는 것이다.
bounding box 회귀는 우리가 처음에 얻은것이 아닌 입력으로 주어진 제안 영역을 변경시켜 얻은 것이다. 제안 영역들도 좋긴하지만 물체를 더 잘 찾아내서 개선할 수 있도록 하는 것이고, 바운딩 박스는 4개의 수로 모수화 할 수 있다보니 구한 bouding box도 4개의 수로 정리할 수 있는 것이다.

위는 다양한 바운딩 박스 변환의 모수화 방법인데, 가장 흔하게 사용되는 것은 우측에 있는 것이다. 제안 영역이 주어지면, 이것을 4개의 수인 tx, ty, th, tw로 변환시키고, 최종 결과 output box는 주어진 제안 영역에다가 변환 값을 반영하여 구하는 것이다.
여기서 모수 값들은 박스크기에 비례하여 평행이동시키며 로그 공간상에서 크기를 조정한다. 제안 영역의 폭과 높이의 스케일을 조정하게 되는데, 이는 CNN을 넣기 전의 input region으로 다시 되돌려주기 위함이라고 한다.
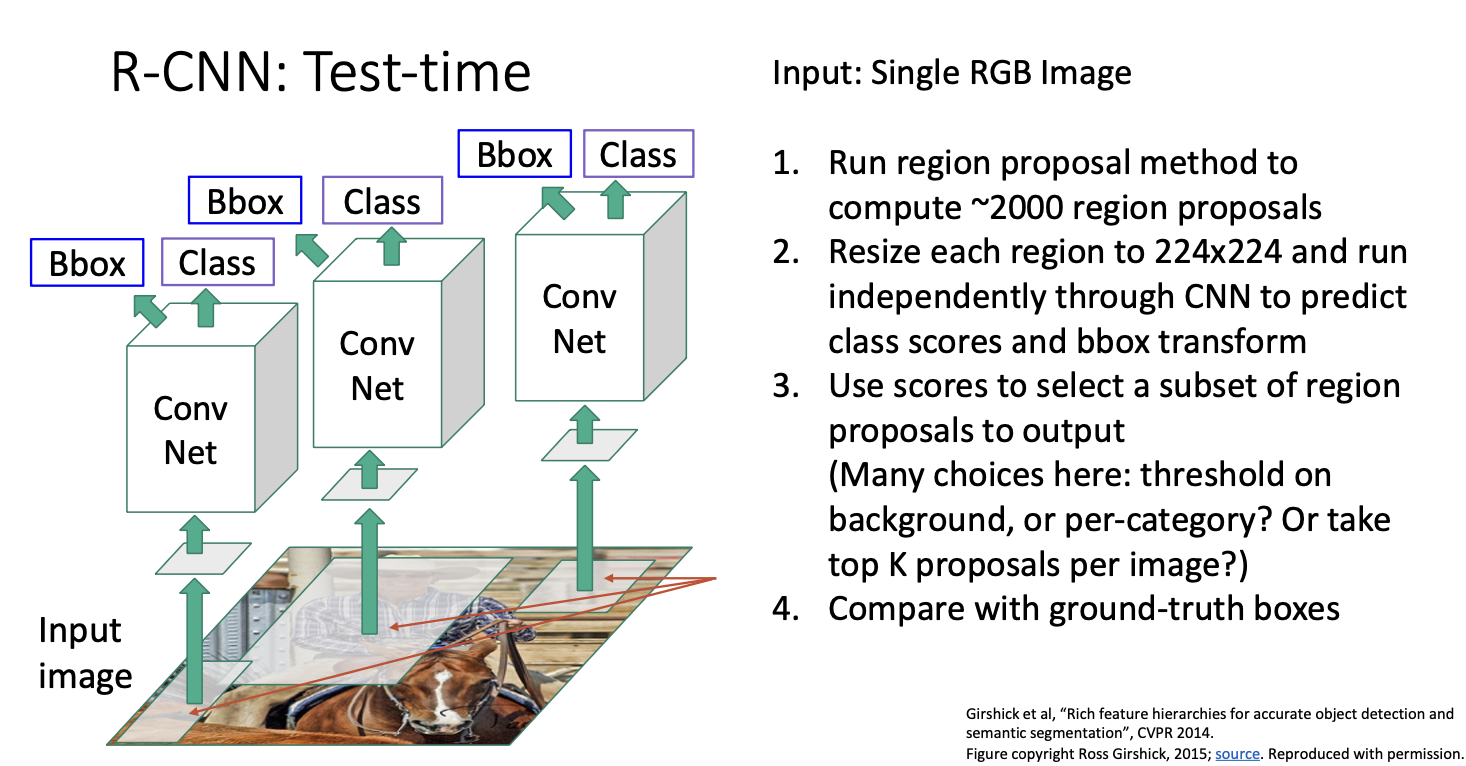
지금까지 살펴본 것은 CNN을 이용한 object detection이다.
- single RGB image를 selective search와 같은 영역 제안 방법을 돌려 2000개 정도의 제안 영역을 구한다.
- 각 제안 영역들을 고정된 크기 224 x 224로 변환하고,
- 독립적으로 CNN을 돌려 카테고리의 합을 구한다.
- box 변환으로 기존 제안 영역의 좌표를 고쳐 구한다.
이제 test time에서는 어플리케이션에 쓸 수 있도록 유한개의 셋을 구하면 된다. 여기서는 다양한 방법들이 있겠지만 사용한 어플리케이션이 무엇이느냐에 따라 방법이 달라진다.
예를 들어, 이미지 당 항상 10개의 객체를 출력하고 싶을 때에는 카테고리 상관없이 배경 score를 기반으로 임계값을 설정하여 가장 낮은 배경 점수를 가진 10개의 region proposals를 출력할 수 있다. 이렇게한다면 최종 예측에 대한 10개의 상자를 얻을 수 있다.
여기서 각 카테고리마다 임계값을 설정해야한다. 그 이유는 우리의 분류 네트워크는 실제로 배경과 각 카테고리에 대한 점수를 제공하는 전체 분포를 출력하고 있기 때문이다. 각 카테고리에 대해 일정한 임계값을 설정하여 해당 카테고리에 대한 분류 점수가 임계값을 초과하는 경우 해당 상자를 최종 출력할 수 있다.
여기서 CNN은 모두 같은 가중치를 공유하고 있다고 한다. 그 이유는 .. 만약! 가중치를 공유하지 않는다면 잘 동작하지 않을 수 있다고 한다. 이미지마다 서로 다른 개수의 제안 영역들을 가질 수 있고, 이미지당 2000개의 고정된 제안 영역을 가진다 해도 개별적으로 다 돌리기 어렵기 때문이다.
그리고 보통은 회전이나 위치 정보를 입력하지 않는다고 한다. 이미지의 왼쪽 상단의 고양이와 오른쪽 하단의 이미지 모두 동일하게 고양이로 보이는 것이 좋을 것이기 때문이다! 실제 이 box의 transform을 다시 살펴보면, 위치 정보를 입력하지 않아도 작동하도록 매개변수화된 방식이었다. 따라서 이미지 내 상자의 위치와 크기에 불변(?)하도록 설계되어 있다고 보면 된다!
근데 왜 224 x 224 크기로 box를 warpping 하는 것일까?
일반적으로 이미지 분류와 동일한 파라미터를 사용한다고 한다. 이미지 전체를 warpping하는 대신 이미지 영역을 warpping하고 있으므로 감지에 대해 사용하는 이미지 해상도는 분류와 동일하게 설정한다. 분류의 경우 일반적으로 224 x 224를 사용하므로 224 x 224크기로 설정한다고 한다.
이제 이러한 bounding box를 평가하는 것도 필요하다. 즉 출력한 상자가 실제로 출력해야할 상자와 유사한지! 를 판단하는 것이다.
그렇다면 두개의 바운딩박스를 비교할 수 있는 메커니즘이 필요하다.

여기서 초록색 상자가 실제 박스이고, 파란색 상자가 우리의 알고리즘이 예측한 박스라고 하자.
그럼 이 파란상자가 초록 상자와 얼마나 일치하는지를 비교할 방법이 필요하다. 이 값들은 모두 실수이기 때문에 정확하게 일치하지 않을 것이다.

일반적으로 두 세트의 바운딩박스를 비교하는 방법 중 하나는 Intersection over Union이라는 메트릭을 사용하는 것이다. 이는 일반적으로 IoU로 평가되며 Jaccard 유사도 또는 Jaccard 지수 라고도 한다. 이를 계산하는 방법은 이름에서 알 수 있듯 두 상자 사이의 유사성을 측정하는 것이다.
그 방법은 다음과 같은데,
- 먼저 두 상자의 교차 영역인 주황색 영역을 계산한다.
- 두 상자의 합집합인 보라색 영역을 계산한다.
- 마지막으로 IoU인 교차영역(주황색 영역)을 합집합 영역 (보라색영역)으로 나눈 비율을 계산한다.
이 예에서는 대략 0.54 정도인데, 이 값은 항상 0과 1의 사이의 숫자일 것이다. 완벽하게 일치하면 1이되고, 두 상자가 완전히 겹치지 않고 아무런 교집합이 존재하지 않는다면 0이 될 것이기 때문이다. 숫자가 높을 수록 두 바운딩 박스가 많이 일치함을 의미힌다.

보통 IoU는
- 0.5 이상이면 꽤 괜찮은 일치
- 0.7 이상이면 일반적으로 꽤 좋은 상태
- 0.9 이상이면 거의 차이를 알아볼 수 없을 정도로 완벽한 상태.
사실 1을 얻을 일은 거의 없을 것이며, 실제 응용 프로그램에서는 이미지의 해상도에 따라 0.9가 실제 몇 픽셀만큼만 떨어진 경우도 많다. 따라서 0.9 정도면 거의 완벽한 것!
그러나 여기서 또 문제가 있는데, 실제로 이러한 객체 탐지 방법은 종종 겹치는 상자 집합을 출력할 수도 있다. 다수의 중복된 상자가 생성되는 경우 이 상자들은 모두 거의 동일한 객체 주변에 있을 것이다.

위와 같은 예시로 실제 이미지의 두 개 강아지에 대한 경우, 객체 탐지기는 보통 하나의 객체 당 정확히 하나의 상자를 출력하지 않는다. 대신 객체 탐지기는 일반적으로 이미지에서 관심있는 각 객체 주변에 매우 가까운 여러 상자들을 출력하게 된다.
따라서 이 중복된 상자들을 처리하기 위한 메커니즘이 필요하다.
Non-Max Suppression (NMS)
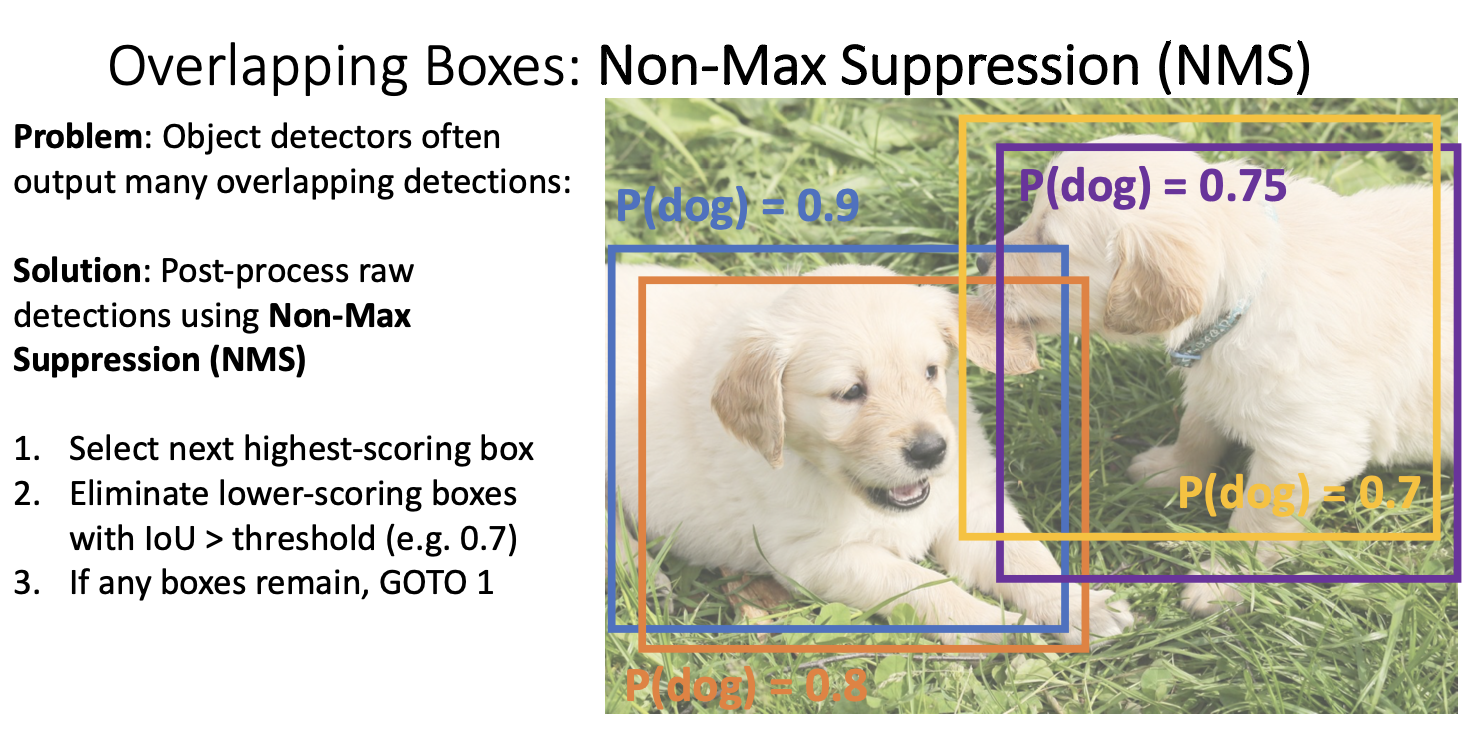
이것을 구현하는 다양한 알고리즘이 있지만 가장 간단한 방법은 탐욕 알고리즘을 사용하는 것이다.
기본적으로 객체 탐지기에서 나온 상자는 이미지 내의 영역에 대한 전체 상자 집합이다. 각 상자에는 해당 상자가 각 카테고리에 속할 확률이 있다. 예를들면 감지기에서 출력된 이 네 상자에 대해 각 상자가 강아지일 확률이 다르게 나올 수 있다는 것이다. 그런 다움 NMS의 탐욕 알고리즘은 이러한 상자들 중 가장 높은 확률의 상자를 선택하고, 다른 중복 상자를 제거하는 방식으로 작동된다. (이 경우에는 파란상자가 선택됨)
그런 다음 최고 점수 상자와 탐지기에 의해 출력된 다른 모든 상자들간의 교차영역을 계산한다. 이 중첩이 일정 임계값 (일반적으로는 0.7과 같은 상대적으로 높은 값을 임계값으로 설정)을 초과하는 경우, 감지기가 서로 다른 객체에 해당하지 않을 가능성이 높다고 판단한다. 그렇다면 중복되었다는 것을 의미한다!

그래서 최고 점수 상자와 임계값보다 높은 IoU를 가지는 상자들은 제거하는 것이다. (여기서는 주황상자가 제거되게 된다.)
주황색 상자를 제거한 후에 다시 첫번째 단계로 돌아가 감지기에 의해 출력된 다음으로 높은 점수 상자를 선택하게 된다. (이 경우엔 보라색 상자가 선택됨) 위의 과정을 반복하여

보라색 상자와 노란 상자의 IoU는 0.74로 노란색 상자가 제거되게 된다.

노란 상자가 제거된 후 최종 결과로는 파란상자와 보라색 상자가 남게되는데, 이들은 완전 분리되어 있으며 높은 중첩을 가지지 않으므로 제거되지 않게 된다.
그치만 NMS알고리즘도 실제로 중복된 상자가 이미지 내에 많은 경우 문제가 발생할 수 있다.

이는 객체 탐지기의 큰 실패 모드 중 하나라고 한다. 이미지에 많은 객체가 중첩되어 있는 경우는 매우 혼잡한 경우인데, 이러한 경우는 구별하기가 매우 어려워 진다.
열심히 많은 연구가 이루어지고 있다고 합니다.
다음은 객체 탐지기가 전체 test set에서 얼마나 잘 수행되고 있는지를 나타내는 전반적인 성능 메트릭에 대한 내용이다.

이미지 분류 작업에서는 꽤 단순한 일이었다. 그냥 argmax를 취해서 그 점수가 실제 label과 같은지를 확인하여 test set에서의 정확도를 계산할 수 있었다. 하지만 OD task에서는 전반적으로 얼마나 잘 수행되는지를 정량화할 수 있어야 한다.
기본적으로 학습된 객체 탐지기가 있고, 이 data set에서 이 객체 탐지기가 얼마나 잘 수행되는지 알려주는 단일 숫자를 얻고자 한다면 평균 밀집도 라는 mean average precision이라는 메트릭을 사용해 계산한다고 한다. 이는 이러한 객체 탐지 분야에서 사용하는 표준 메트릭이다.
이를 위해 먼저
- 학습한 객체 탐지기를 test set의 모든 이미지에 대해 실행한다.
- 다음 test set에서 중복된 감지를 제거하기 위해 NMS를 사용한다. (각 상자에 대해 분류 점수를 가지고 있음)
- 평균 정밀도를 개별적으로 계산
평균 정밀도란! 재헌율 곡선 아래 면적 (Area Under the Precision-Recall Curve)를 나타냄.
이에 대해 좀 더 자세히 살펴보면 이 과정은 카테고리 별로 개별적으로 진행하게 된다.

여기서 파란색 박스는 검출기로부터 얻은 강아지 카테고리들의 scroe 확률로 가장큰 것은 0.99, 두번째로 큰 것은 0.95 이다.
다음 주황색 박스는 test set의 실제 강아지 영역을 나타내는 것이다.
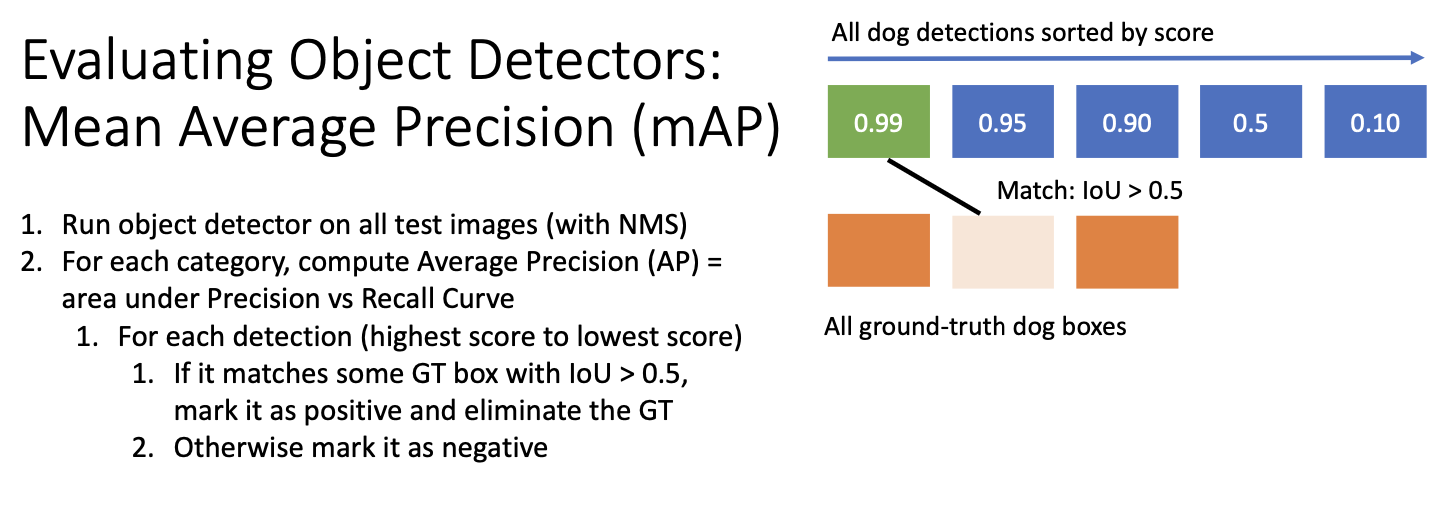
score에 따라 정렬한 검출 영역과 실제 영역의 IoU가 0.5 이상으로 임계화가 되면 매칭을 하는 것이다.
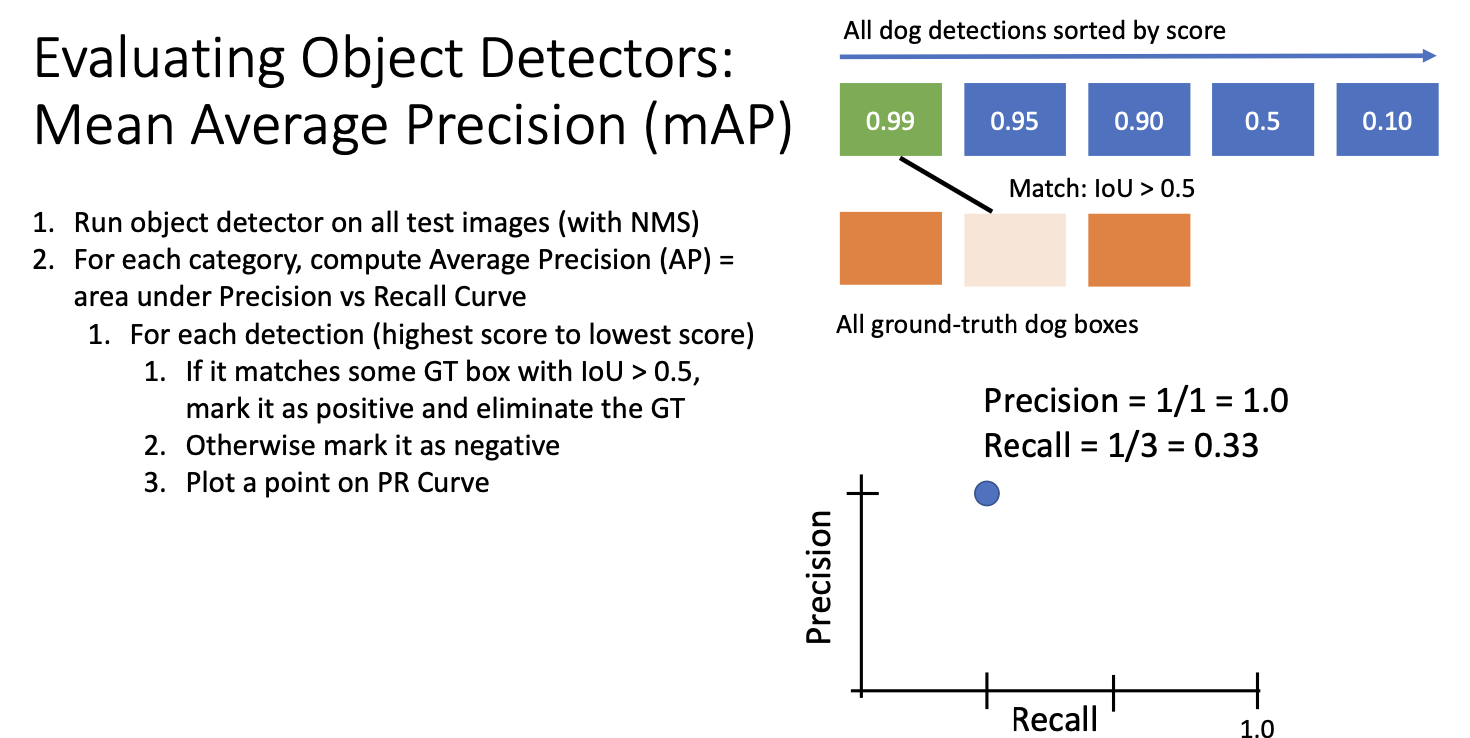
그렇게 올바르게 검출을 하고 나면, 정밀도 재현율 곡선에서 한 점의 위치를 계산할 수 있다. 정밀도 precision은 검출 결과가 실제로 참인 경우의 비율이고, 재현율 recall은 전체 ground truth 중에서 실제로 맞을 비율이다.

다음 이 과정을 반복하여 두번째로 높은 점수의 강아지 영역이 실제 값과 일치한다고 가정하면 정밀도-재현율 곡선상에 또 다른 점이 생기게 된다. 두 감지를 모두 참으로 고려하고 있으므로 정밀도는 2/2, 즉 100%이고, 재현율은 2/3이 된다.
이러한 방식을 계속 진행하면

세번째 과정에서 실제로 거짓이었다면, 새로운 정밀도 재헌율 곡선상의 점이 된다.
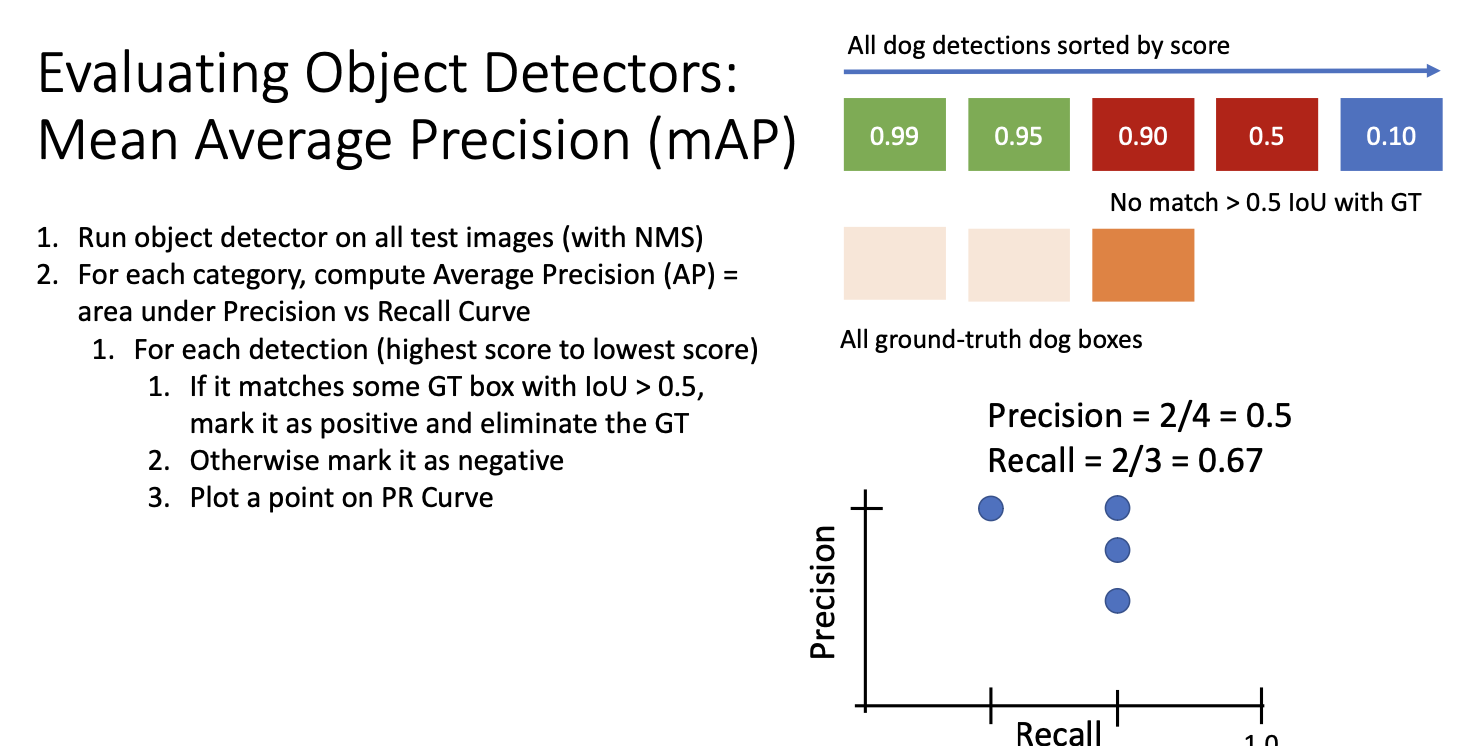
다음의 경우도 거짓이라면 재현율은 그대로이나 정밀도는 떨어지게 된다.
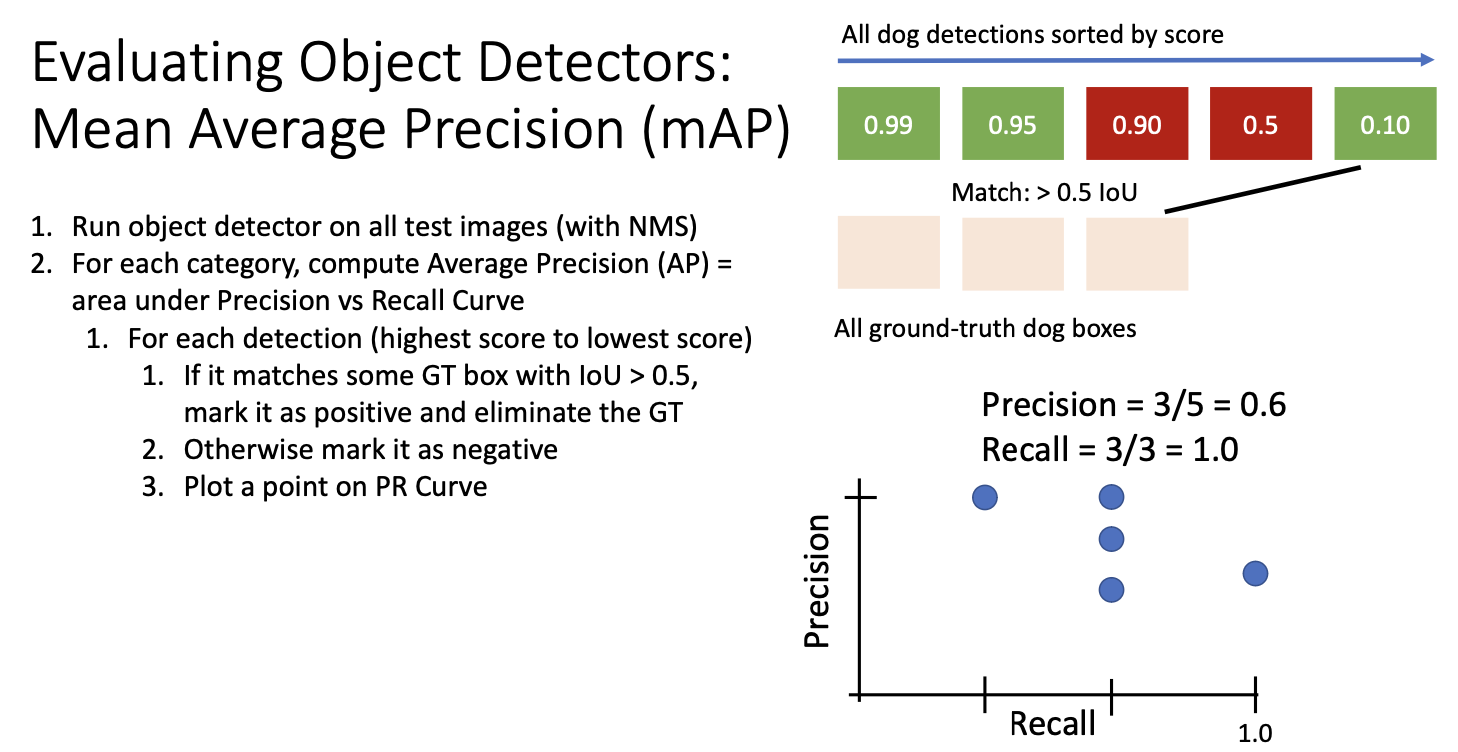
마지막 영역이 긍정인 경우, 마지막 groud truth와 매치되어 정밀도는 5개의 검출 결과중 3개를 참임으로 3/5이고,
재현율은 실제 ground truth를 모두 찾아내었으므로 1이 된다.
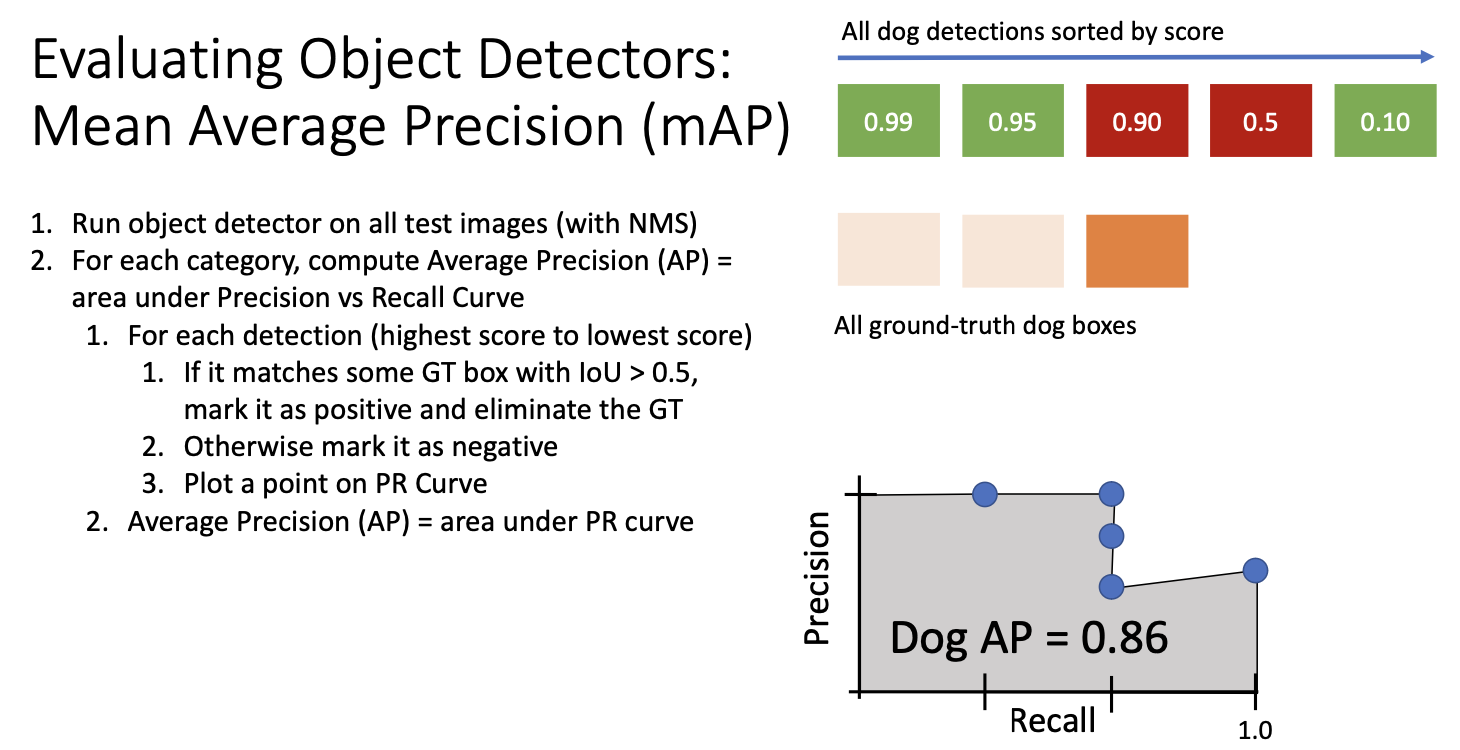
이제 여러개의 점을 통해 정밀도-재현율 곡선을 구성하게 된다. 곡선 아래 면적을 계산하여 평균 정밀도를 얻게되는데,
정밀도-재현율 곡선 아래의 면적이 클수록 모델이 성능이 우수한 것을 뜻한다.
이는 정밀도-재현율 곡선 위의 점들을 모두 floating한 후 전체 곡선을 그린 다음, 그 아래 영역을 계산할 수 있다. 이는 0에서 1 사이의 숫자여야 하는데 0은 성능이 나쁨을 의미, 1은 매우 우수함을 의미한다.
이 곡선 아래 면적은 해당 범주에 대한 평균 정밀도 Mean Average Precision 또는, mAP라고 불린다.
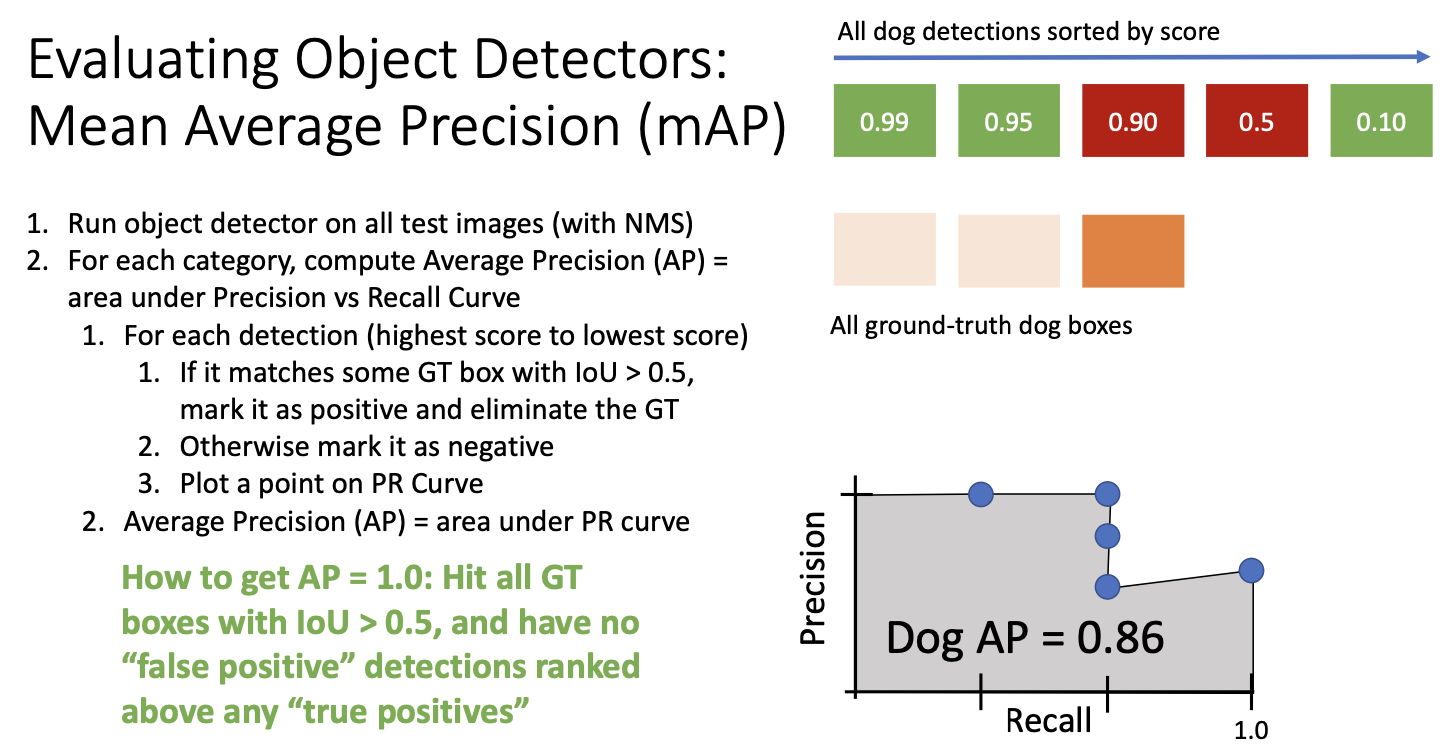
이 경우 mAP가 0.86인데, 이 숫자가 의미하는 바는 다음과 같다. 먼저 어떻게 하면 ap 1.0을 얻을 수 있는지 생각해보자!
우리의 true가 false보다 먼저 나와야 한다. 즉 모델에서 출력한 상위 감지가 모두 참!! 이어야 한다는 것이다. 또한 중복 감지가 없어야 한다. 더하여 모든 감지가 적어도 IoU 0.5이상이 나와야 함을 의미한다. -> 너무 어려워!!
그럼에도 ap 지표를 사용하는 이유는?
서로 다른 응용 분야에서 얼마나 많은 물체를 맞출 것인지, 얼마나 많은 물체를 놓칠 것인지에 대한 서로 다른 선택사항이 있을 수 있기 때문이다. 예를 들어 자율주행 에서는 주변의 차량을 놓치지 않는 것이 매우 중요한데, 다른 응용 분야에서는 false의 값이 그렇게 중요하지 않을 수도 있다. 따라서 이러한 평균 정밀도는 모든 가능한 지점을 종합적으로 요약하는 효과가 있다.

실제로는 강아지 뿐만 아니라 각 객체 범주에 대해 이 전체 절차를 반복한 뒤 각 범주에 대한 평균 정밀도를 얻은 다음 그것의 또 평균을 내어 계산한다고 한다.
하지만 이게 잘못 될수도 있다. 평균 정밀도의 평균을 계산할 때 박스의 위치 추정이 잘 되는지 고려하지 않고 검출된 박스와 graund truth와 IoU만 보고 매칭하기 때문이다.

실제 사용시에는 이 전체 과정을 다른 IoU 임계치로 돌려볼 수 있고, 이렇게 다양한 임계치 값에 대해 mAP 값을 얻을 수 있다.
이 과정은 객체 검출기를 평가하는데 매우 복잡하지만 실제로 사용하는만큼 유용한 방법이라고 한다!
다시 Object Detection으로 돌아가부자..
R-CNN은 영역 기반으로 객체를 잘 탐지했었다.
그럼에도 문제점이 존재했는데!

매우 느리다는 문제점이다!
선택적 탐색 방법으로 얻은 각 제안 영역들에 대해서 CNN을 통한 연산을 하기 때문이다. 선택적 탐색 방법은 2000개의 제안 영역들을 만드는데 이미지로부터 2000개의 forward pass를 해야하니까 꽤 계산비용이 크며, 매번 이미지들을 실시간으로 돌리는 것이 어렵다.
해결해야해!
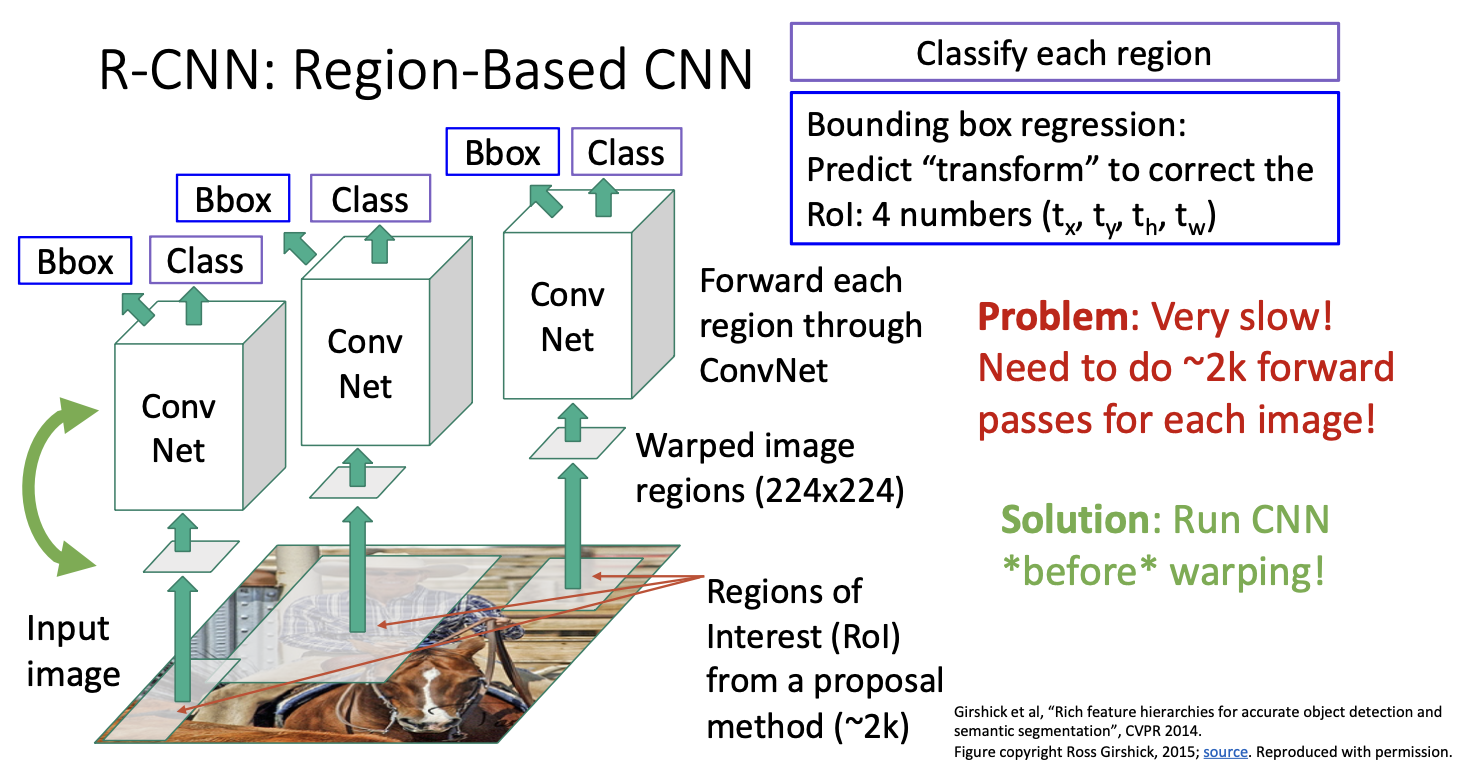
더 빠르게 만들어야겠지!
CNN을 돌리고 나서 warpping을 하는 것이다! 그렇게 되면 서로 다른 영역들간에 많은 계산량을 공유(?)할 수 있게 된다.
어떻게 동작하는 것인지 자세히 알아보자.
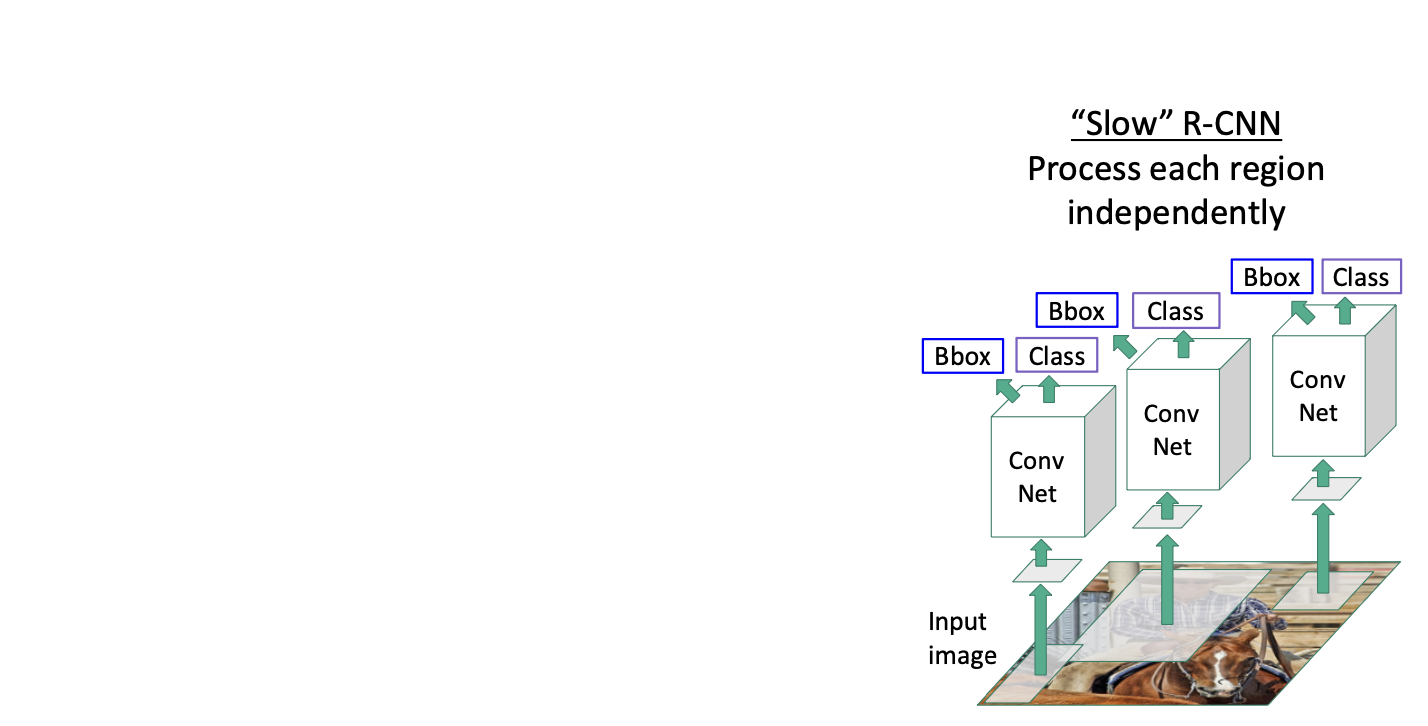
현재는 느려서 slow RCNN이라고도 불린다고 한다. 그래서 대안적인 방법은 fast CNN! 이다.

Fast CNN은 기본적으로 slow와 동일하지만, CNN과 region warpping의 순서를 바꾸어 처리 속도를 높이는 것인데, 입력 이미지를 가져와 단일 CNN에서 고해상도로 전체 이미지를 처리하게 된다. 여기에는 fully connected가 없으며 모두 CNN만 사용한다.
이 레어이의 출력은 고해상도 이미지에 대한 convolution 특징을 제공하는 feature map이 된다.
여기서 backbone network! 가 등장한다. 이 이미지를 돌리는 모델을 가리키는데, AlexNet이나 VGG, ResNet 등 사용하고 싶은 걸 쓰면 된다.

이제 입력 이미지의 픽셀을 자르는 대신 이러한 지역 제한을 convolutional feature map에 투영하고 특징 맵 자체에서 크롭을 적용한다. 쉽게 말하면 CNN 백본 네트워크로부터 얻은 feature map을 잘라낸다고 생각하면 된다.

그러고 나서 각 영역들마다 가벼운 신경망을 돌리고

출력으로 각 영역별 분류 score와 bouding box 회귀 변환 값들을 얻게된다.
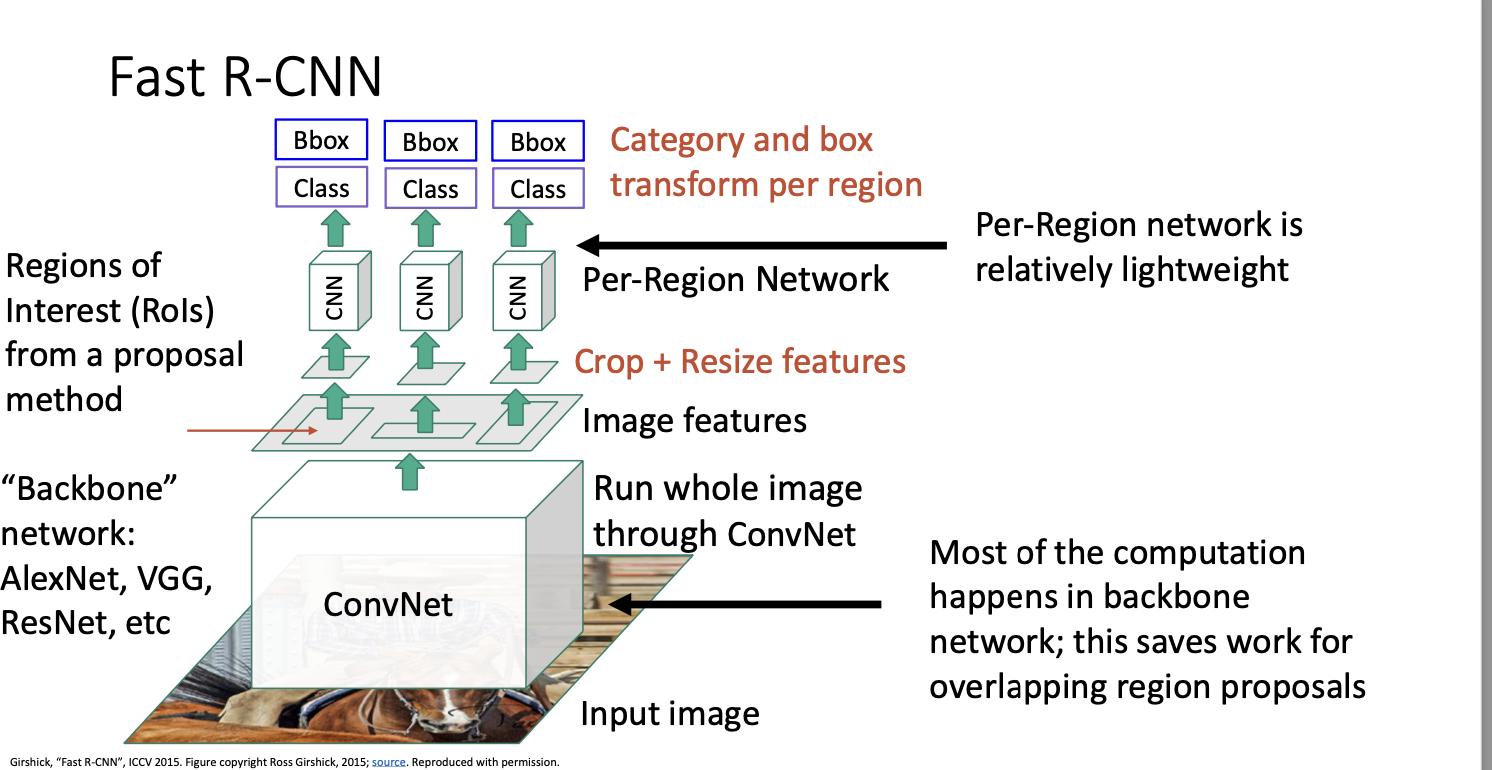
이 과정은 아주 빠른데, 그 이유는 대부분의 계산 과정은 backbone network에서 일어나기에 각 영역마다 돌아가는 신경망은 아주 작고 가볍다보니 빠른것이다. 즉 이미지당 2000번의 전방향 패스가 아닌, 백본 네트워크에서 한 번의 전방향패스만으로도 빠르게 처리할 수 있게 된 것이다.
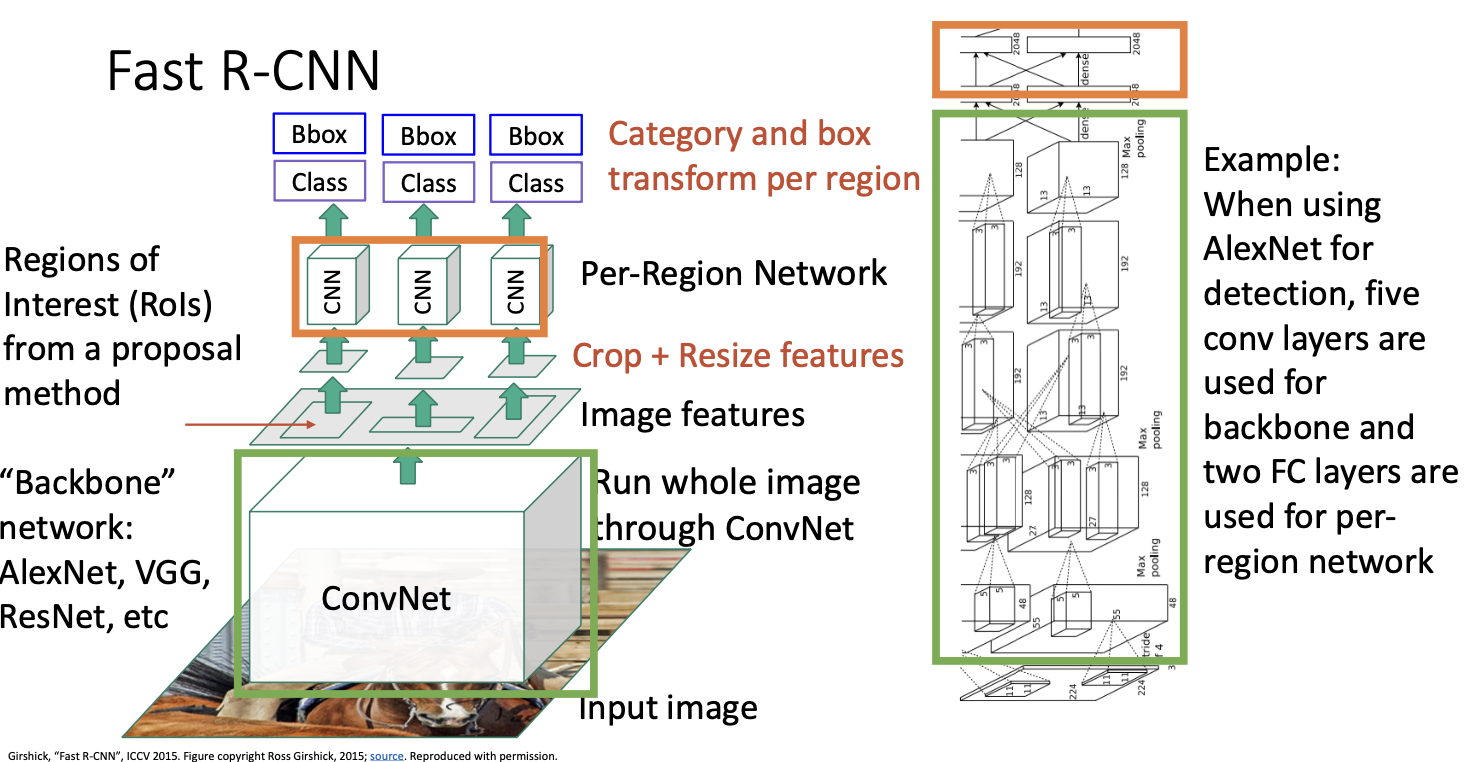
예를 들어 AlexNet을 사용한 Fast R-CNN을 상상해보면, 백본은 AlexNet의 모든 CNN으로 이루어질 것이고, 지역별 네트워크는 단순히 네트워크의 끝에 있는 2개의 fully-connected layer일 것이다. 따라서 이 두 layer는 비교적 계산이 빠르기 때문에 여러 region에 대해서도 빠를 것이다.

Residual Network와 같은 경우에는 기본적으로 마지막 CNN stage를 region network로 사용한다. 나머지는 백본 네트워크로 사용하는데, 이렇게 함으로써 대부부분의 계산이 백본 네트워크에서 모든 region network에 공유되므로 계산을 절약할 수 있다.
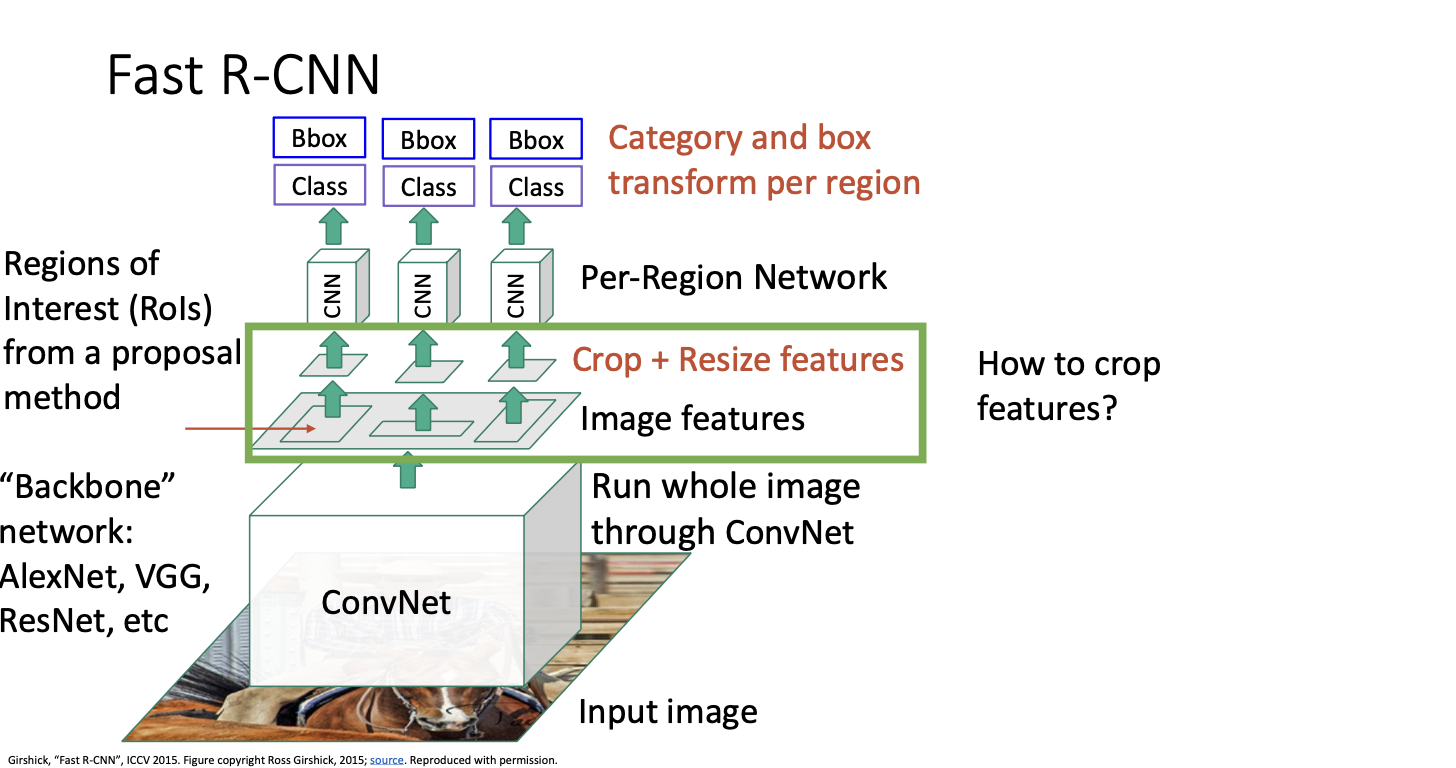
그런데 이러한 특징을 어떻게 자르는 것인지! 정확히 무엇을 의미하는 것인지에 대한 의문을 가질 수 있다.
왜냐하면 역전파를 수행하기 위해서는 이러한 특징들의 가중치에 대한 역전파가 실제로 필요하기 때문이다. -> 미분이 가능하도록 잘라내어야겠지!
ROI : Region Of Interest

특징을 미분이 가능하도록 잘라내는 방법은 ROI (Region Of Interest)라고 부르는 연산자를 사용하면 된다.
위와같은 입력 이미지와 입력 이미지에 대한 제안 영역이 주어지면,
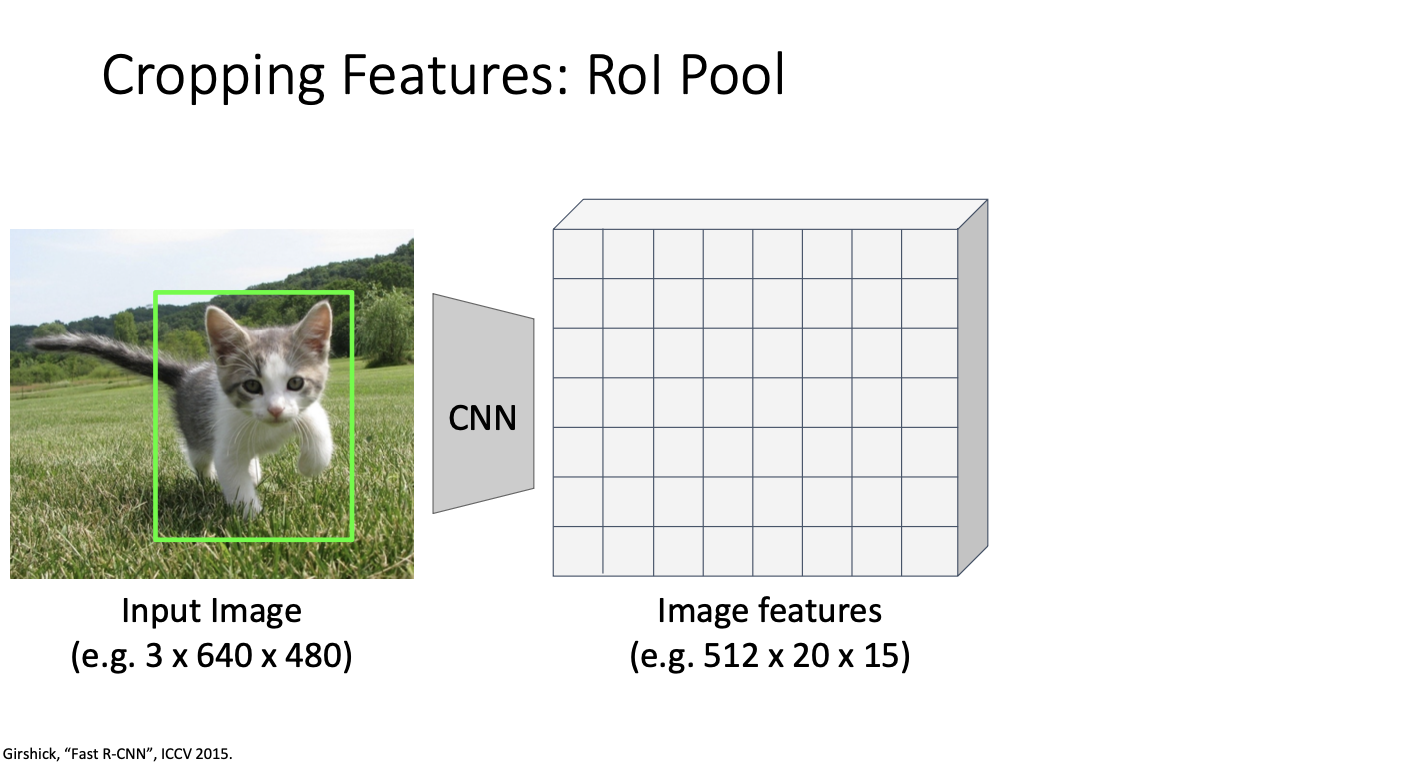
backbone network를 돌려서 위와 같은 CNN연산을 통해 이미지 특징을 얻는다.
데이터 형태를 정리하자면
- input image : RGB channeal (3) 과 공간 크기 640 x 480
- image featrue : 512 차원과 공간적 크기 20 x 15

이 신경망은 완전히 CNN으로만 이루어져있기 때문에 feature map의 각 지점은 입력 이미지의 지점과 대응된다. 그래서 region proposlas를 해당 feature map으로 투영할 수 있다. 이 다음 특징들을 딸깍 맞출(스냅)수 있는데, 사영한 뒤에 제안 영역이 합성곱 grid에 완전히 일치하지 않을 수 있다.
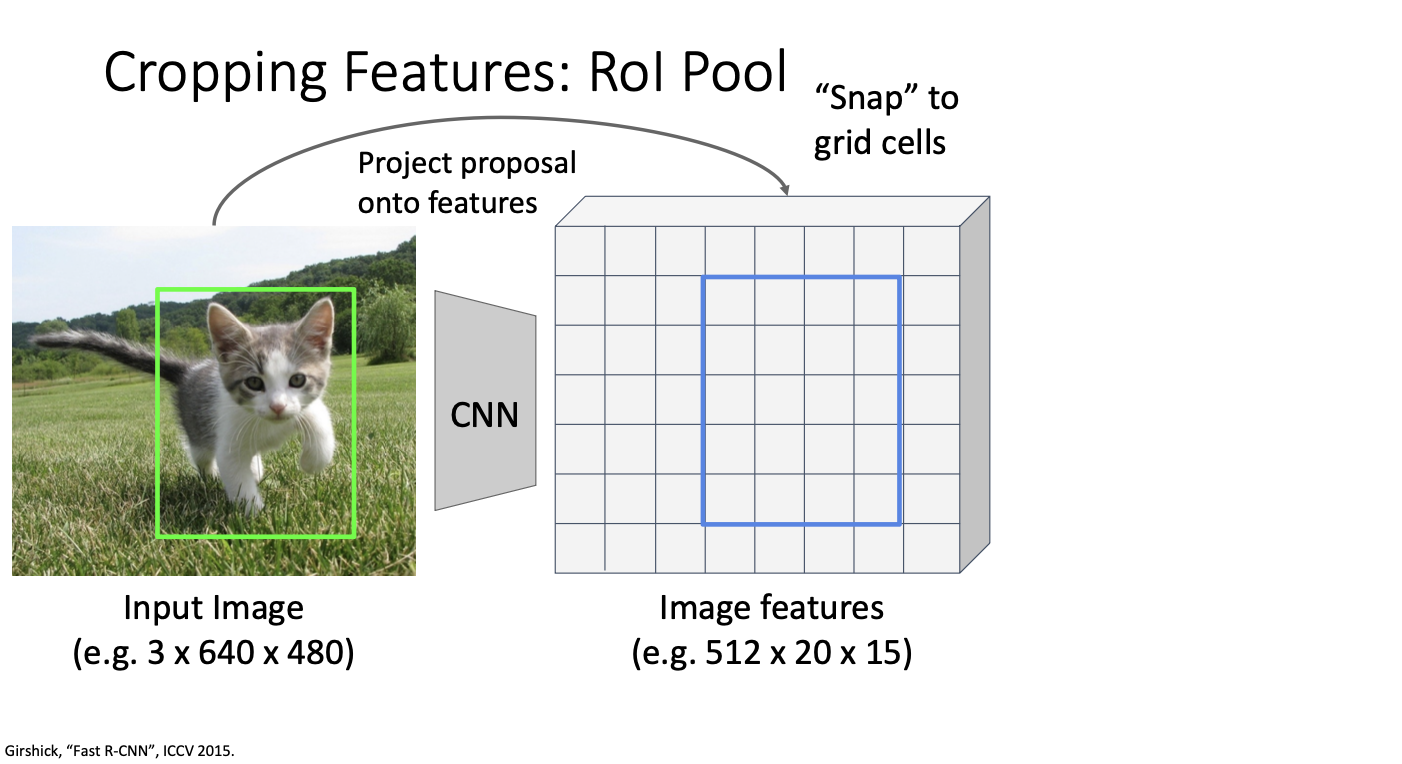
그래서 위와 같이 합성곱 grid 격자에 잘 맞춰지도록 스냅!을 시키고,

이제 ROI pooling을 적용시키는데, 2x2 pooling을 할 수 있도록 제안 영역을 대략적으로 2x2의 subregions으로 나눈 다음,
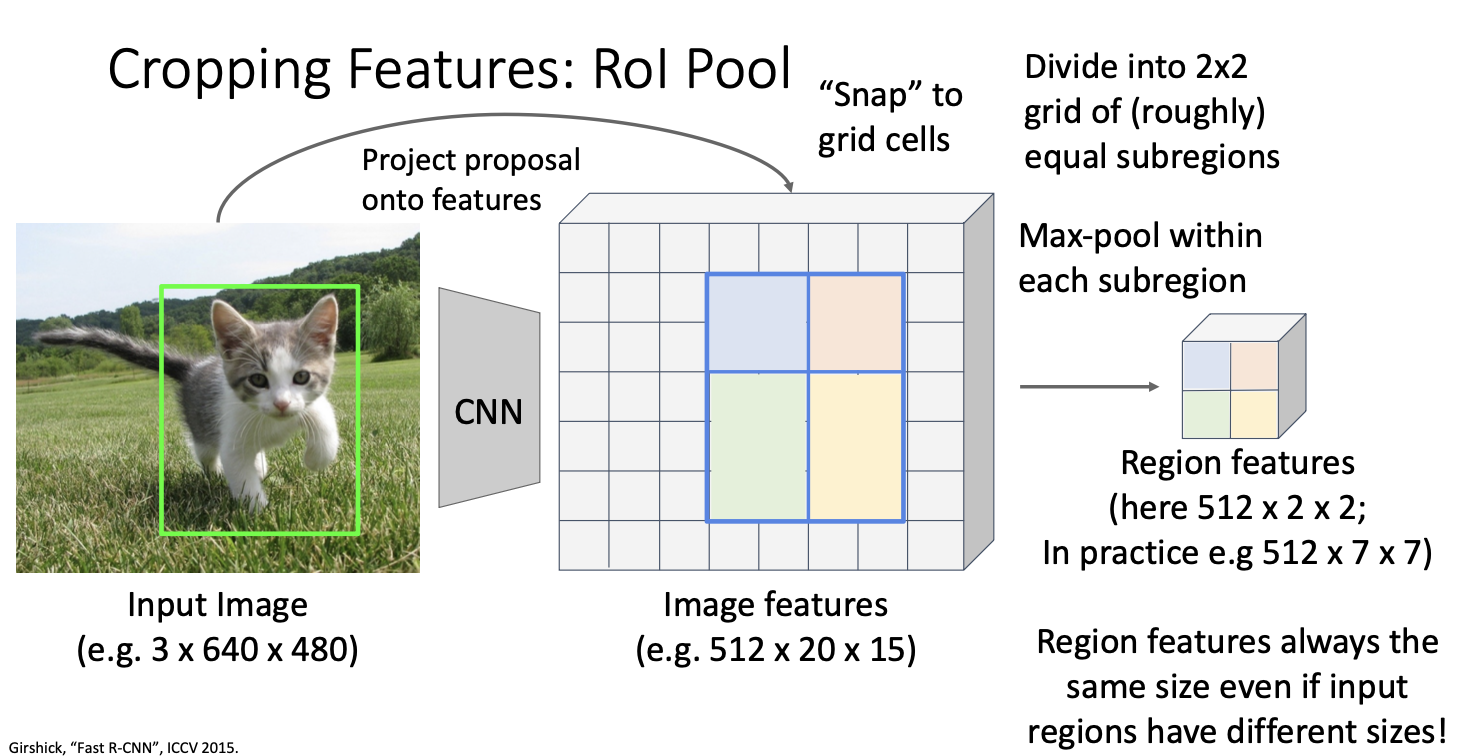
이를 위해 맞춘 지역 제안을 grid cell에 따라 정렬한 뒤 그 후에 각 grid cell 내에서 max poolig을 수행한다.
이러한 과정을 통해 파란색 영역은 2 x 2 x 512 차원이 되며, 각 부분 영역 내에 max poolig을 수행하여 출력으로 512차원 벡터를 출력한다. 이와 유사하게 녹색 영역은 3x2x512차원 벡터를 출력한다. 이를 통해 feature를 미분 가능한 방식으로 자를 수 있고, 최종적으로 부분 영역에 대해 poolig을 수행하여 특징을 추출한다.
이 과정을 통해 input region proposal이 다양한 크기를 가지더라도 ROI pooling 연산자의 출력은 항상 동일한 고정 크기의 텐서가 되어 이를 다음 CNN 레이어에 전달할 수 있게 된다. 이러한 process로 역전파를 수행할 수 있다. 일반적으로 max poolig을 통해 backpropagation을 수행하는 것과 같은 방식으로 upstream gradiet를 region feature에 전파하고, 이를 통해 해당 영역의 이미지 특징에 전파하게 된다.
그러나! 이러한 snapping과 region의 크기가 다를 수 있는 것이 문제가 될 수 있다!
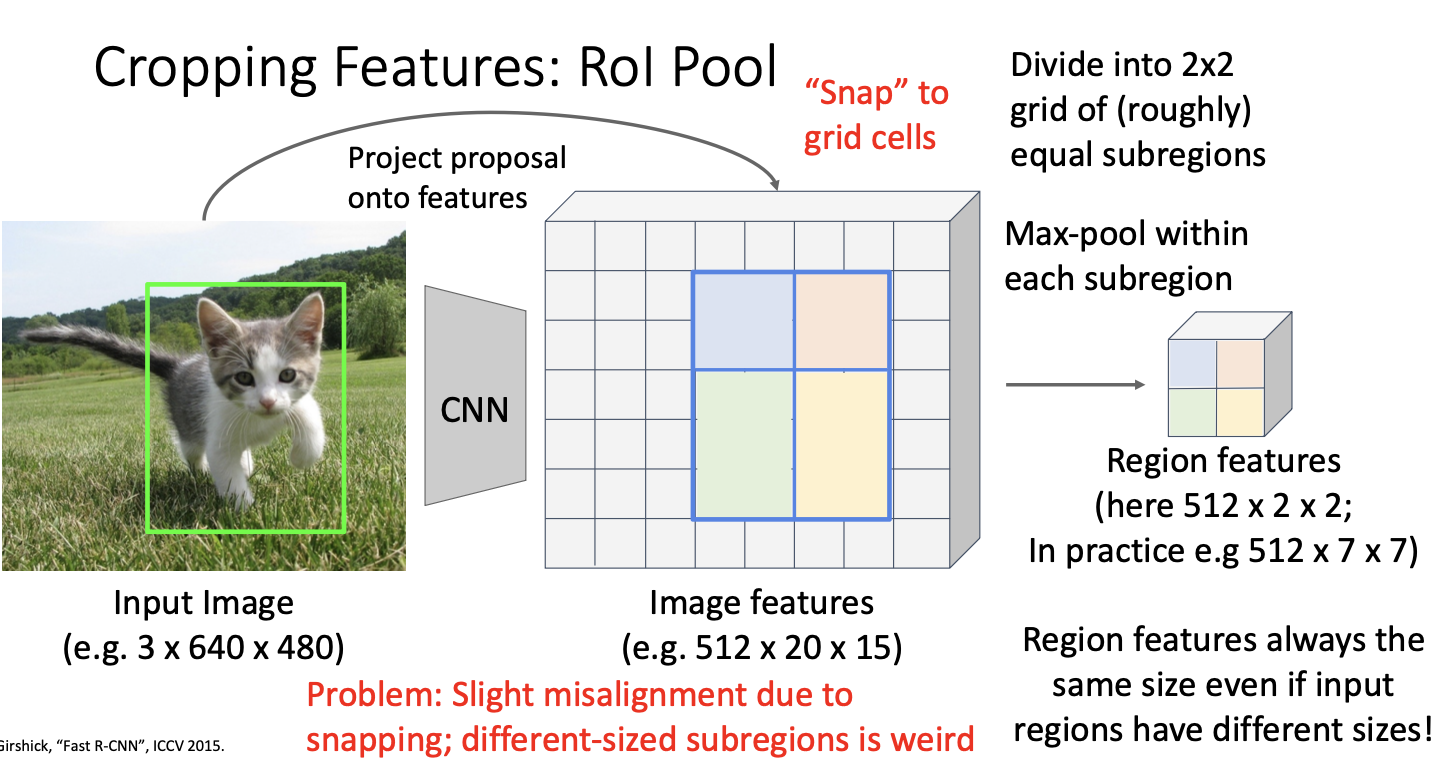
위에서 초록색과 파란색 영역이 다른 크기일수도 있다는 사실이다. 그래서 등장한 것이!
ROI Align
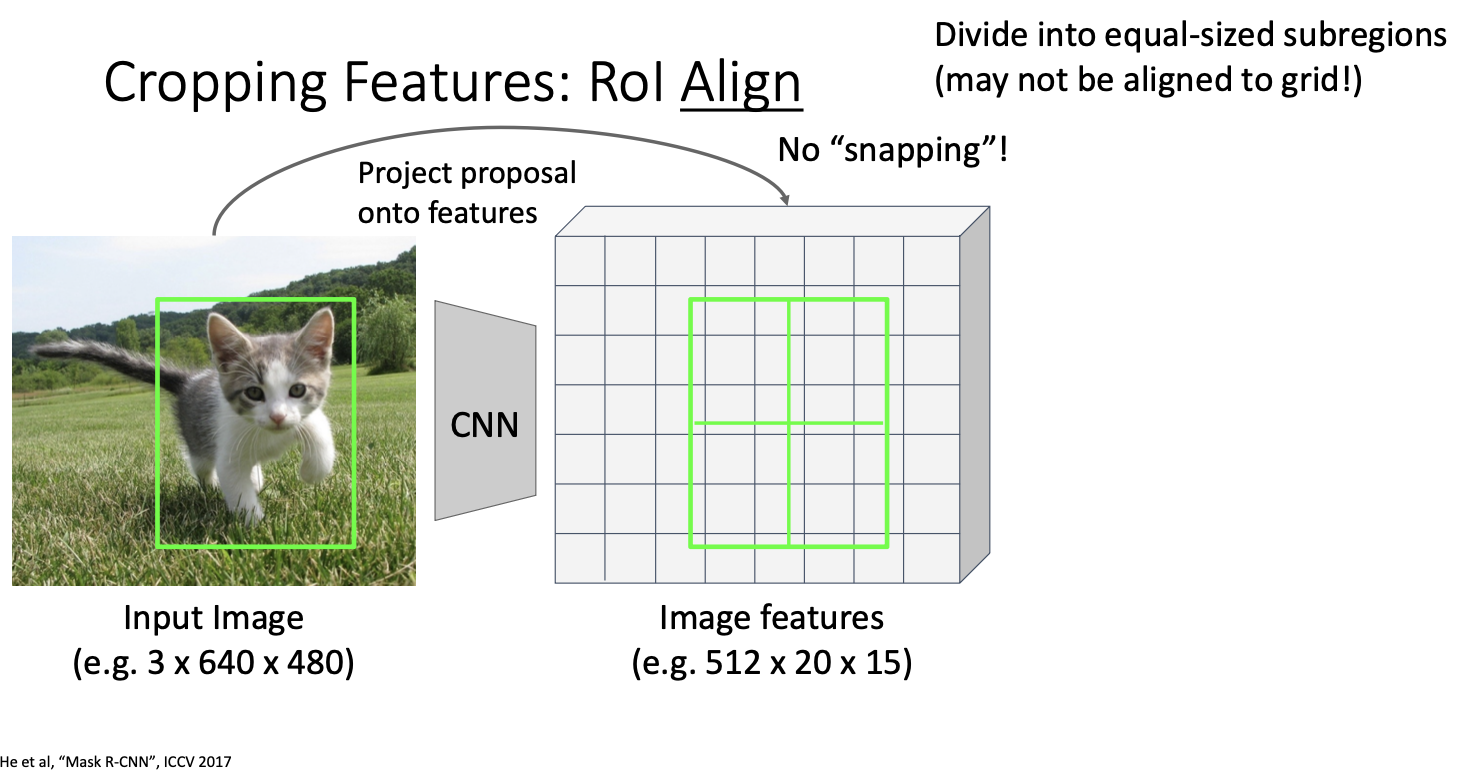
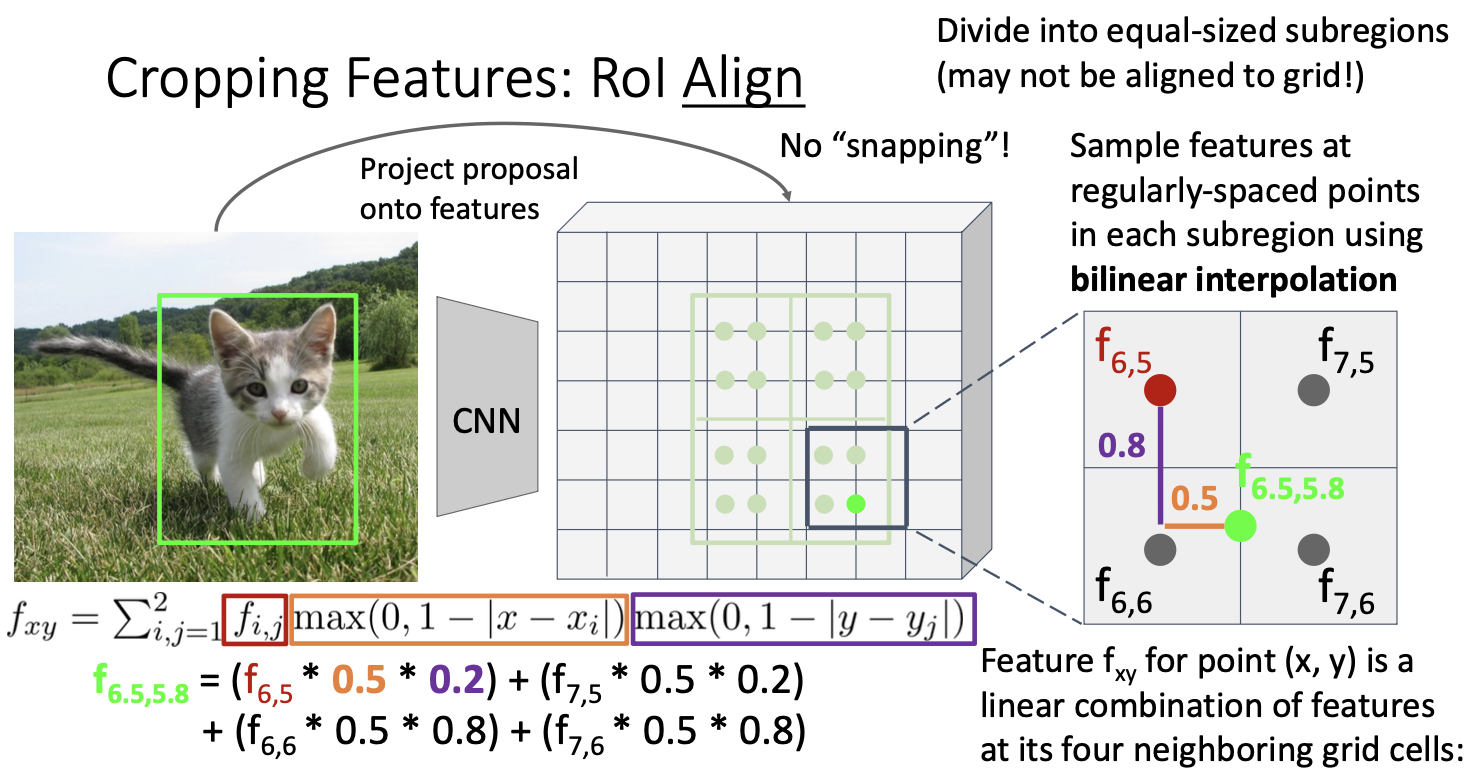
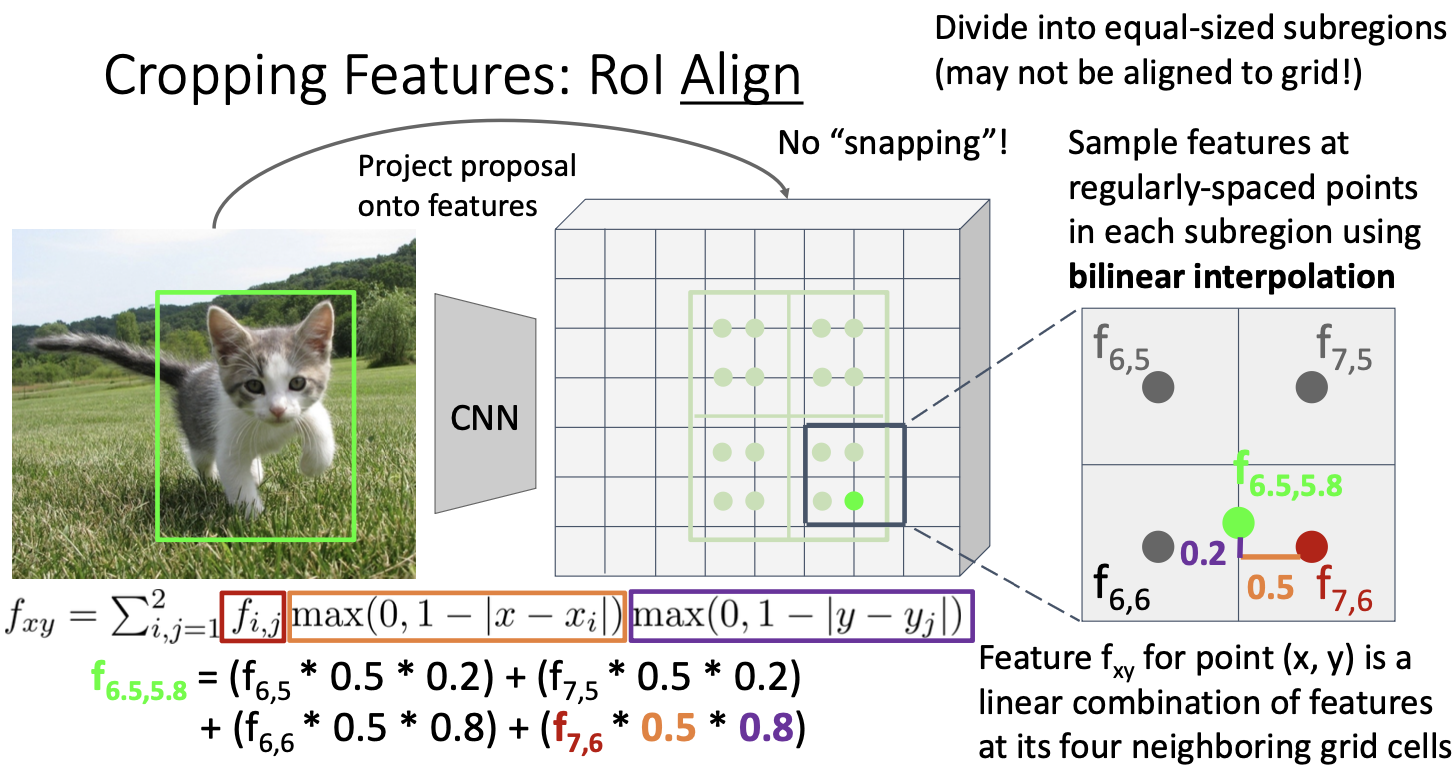
snapping을 하지 않고 이뿌게 정렬하기 위해 bilinear interpolation을 사용하는 것이다. 간단히 말하면, Input feature와 output feature 간에 더 나은 정렬을 가능하게 하는 것이다.

Fast R-CNN vs Slow R-CNN

기본적으로 위 둘의 차이점은 convolution, cropping, warping의 순서를 바꾼 것이다.
그렇다면 Fast R-CNN은 얼마나 더 빠를까?
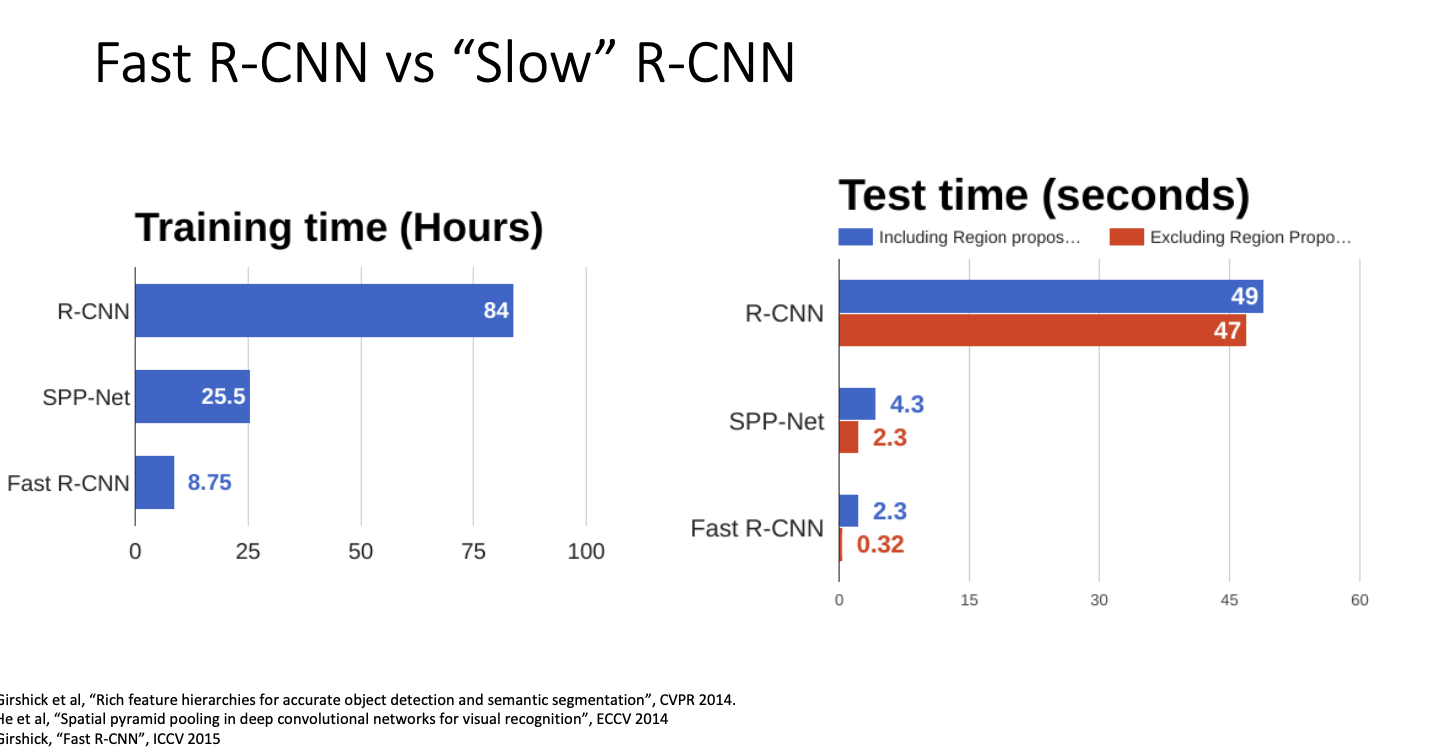
훈련 시간과 추론 시간을 살펴보자! RCNN을 훈련하는 데는 몇 년 전에 사용된 매우 오래된 GPU에서 약 84시간이 걸렸다. 그치만 동일한 GPU 설정에서 Fast RCNN은 약 10배가 더 빨랐다고 한다.
추론 시간에서도 Fast R-CNN이 매우 빨랐다. 이유는 계속 언급했듯 서로 다른 이미지 영역 간에 계산을 공유하기 때문이다.
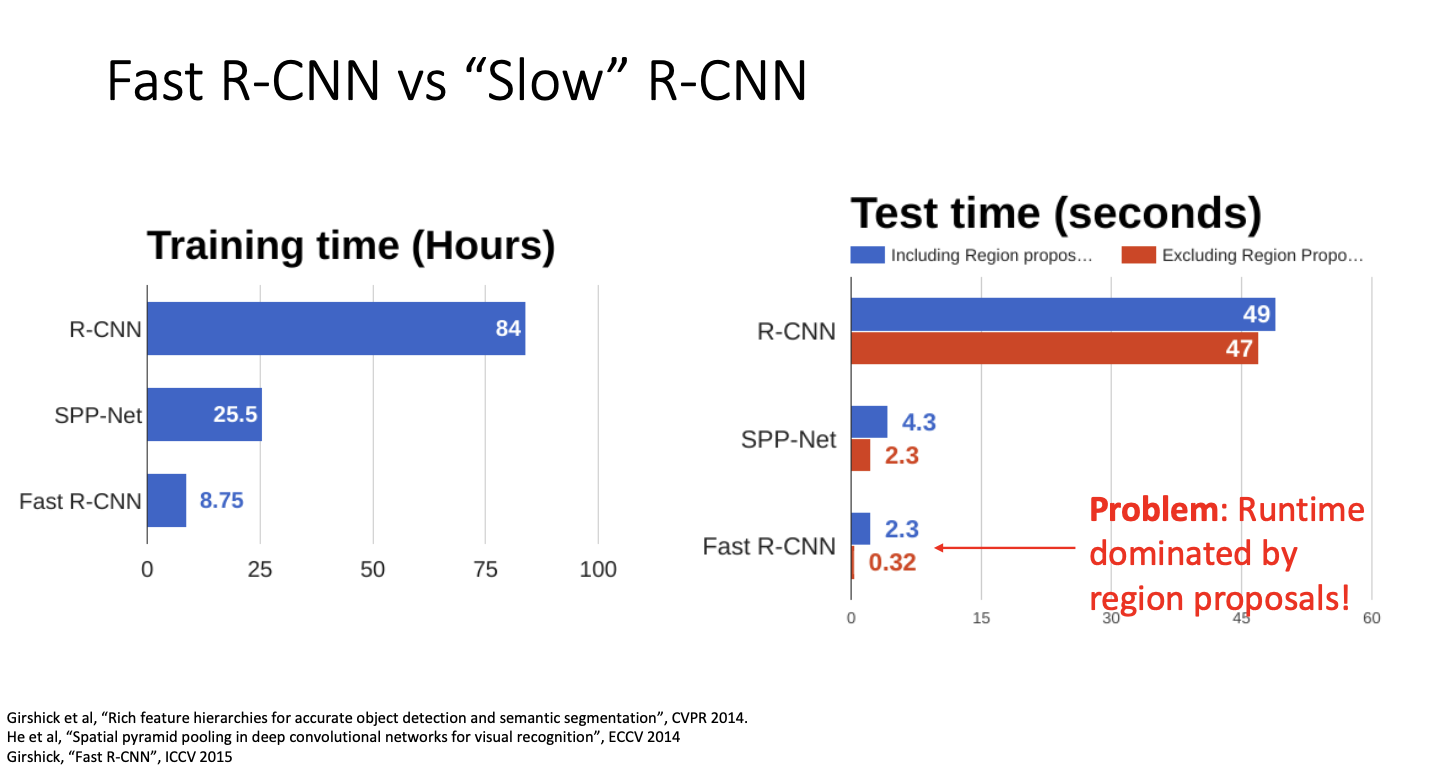
그러나 흥미로운점은! Fast RCNN은 region proposal 계산에 소요된다는 것이다.
region proposal은 selective search라고 부르는 경험적 휴리스틱 알고리즘을 사용하기 때문인데, 이 알고리즘이 cpu에서 동작하기 때문이다. 그래서 fast RCNN을 보면 동작 시간의 90%가 이 제안 영역을 계산하는데 사용한다.
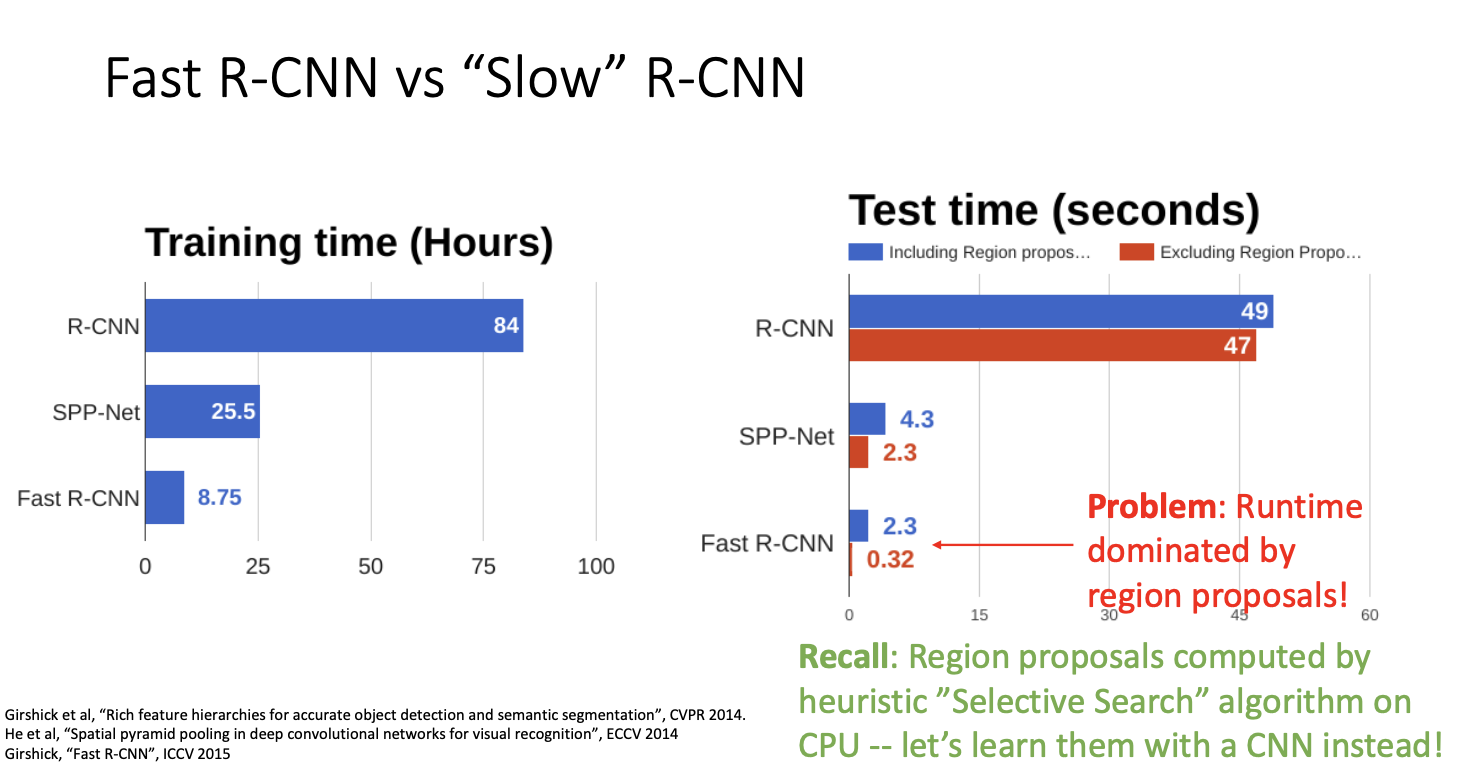
여기서 이것을 경험적 알고리즘으로 제안 영역을 구하는 대신, 이것을 CNN으로 대체하여 구하면 더 효율적일 것이다.
그렇다면 이 object detection 시스템을 훨씬 개선할 수 있을 것이다.
그것이 바로 Faster R-CNN이다.
Faster R-CNN
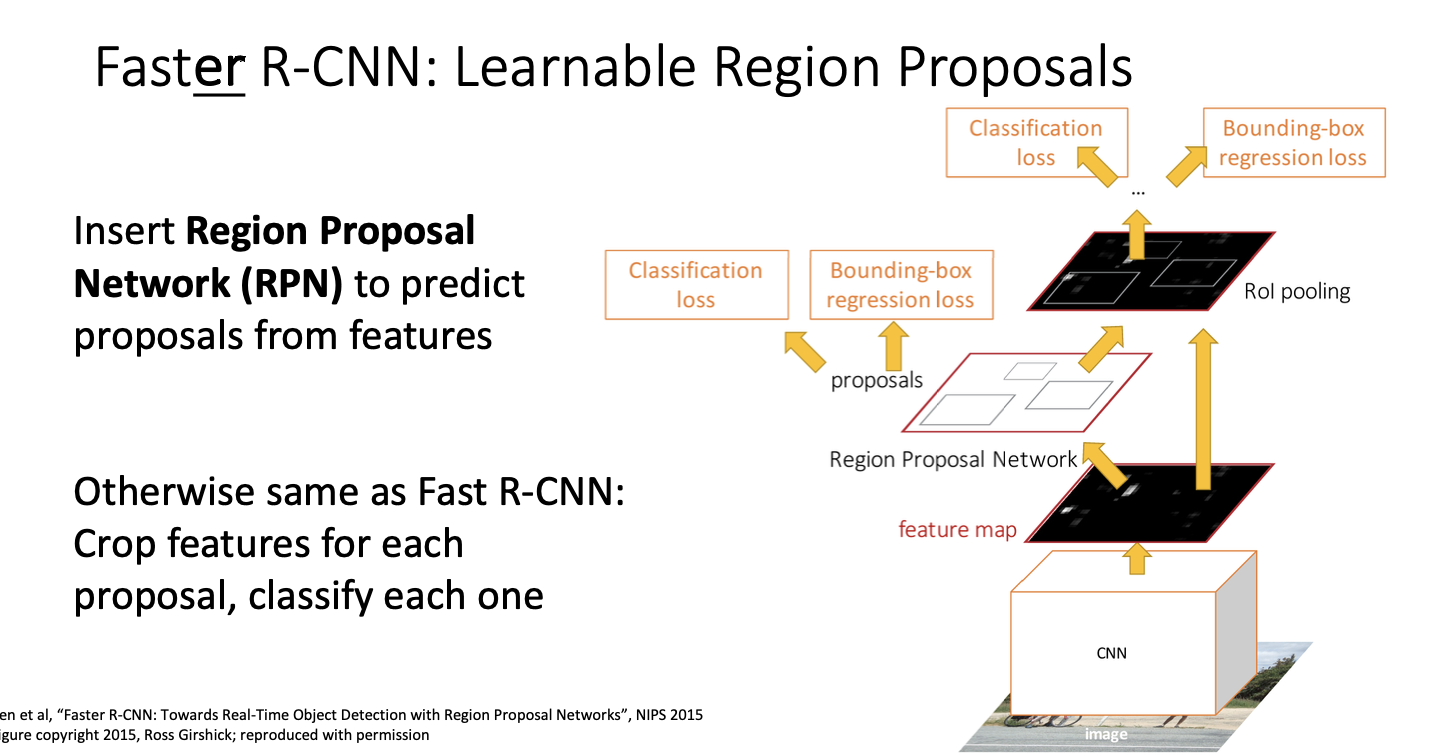
이 메서드는 지역 제안을 계산하기 위해 CNN을 사용하는 방식으로 동작한다.
동작 과정은 fast와 비슷한데, 백본 네트워크 뒤에 제안 영역 신경망, region proposal network, RPN이라는 작은 신경망이 추가되어 region proposal들을 예측하게 된다.
입력 이미지를 가지고 백본 네트워크에 통과시켜 이미지 수준의 특징을 얻어 이를 region network에 전달한다.
그 후에는 fast와 동일한 과정을 수행하게 된다. 미분 가능한 cropping을 수행하고, 각 지역에 대한 작은 네트워크를 이용하여 최종적인 분류 및 bounding box 변환을 예측한다.
그럼 proposal network는 어떻게 작동할까?

다시 한 번 동일한 백본 네트워크를 기반으로 하고있기에 원래의 input image를 백본 네트워크에 통과시켜 상대적으로 높은 해상도의 이미지를 얻는다. 예를 들어 512x20x15와 같은 해상도가 될 것.
여기서 아이디어는 백본 신경망으로 얻은 이미지의 특징은 입력 이미지의 특징과 일치하다는 것이다.
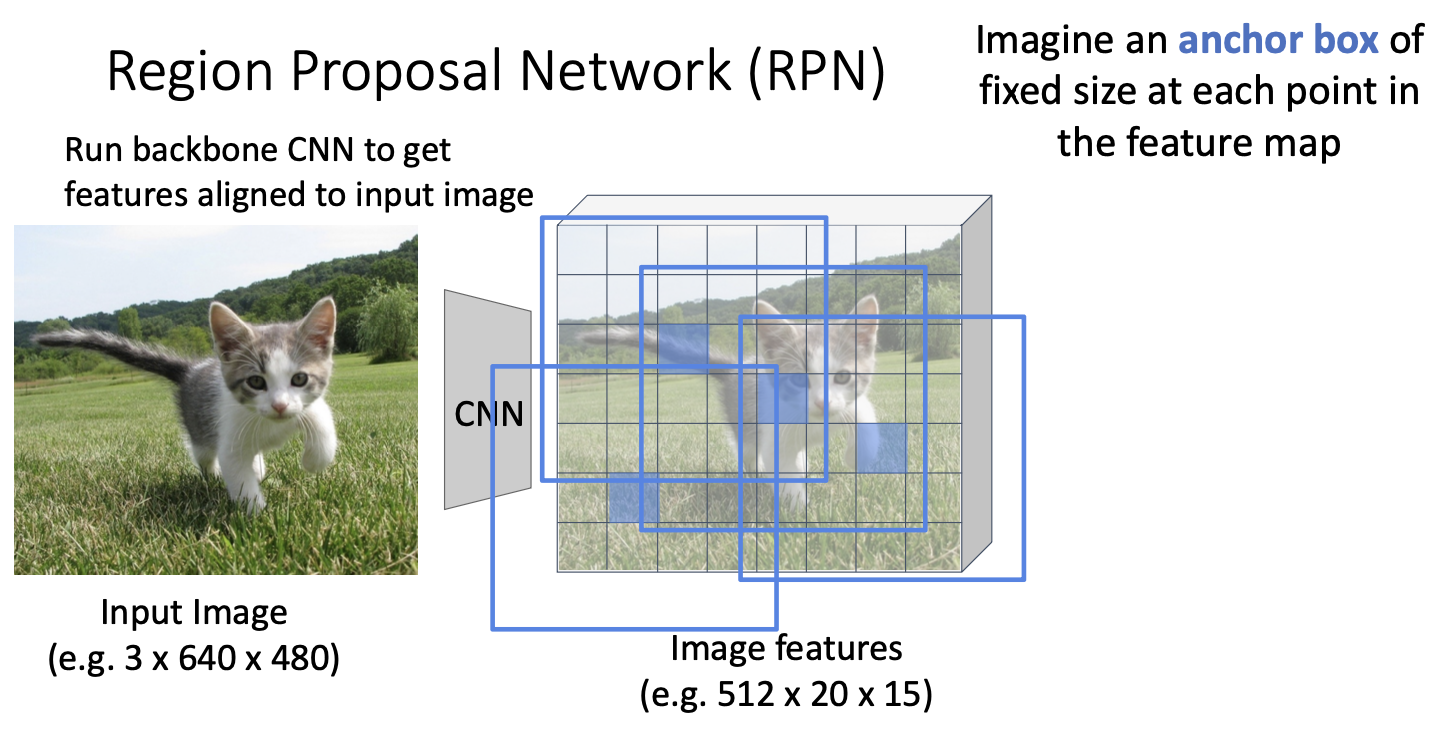
여기서 우리가 해볼 수 있는 것은 feature map의 각 지점에서 anchor box라고 하는 고정된 크기와 고정된 가로세로 비율을 갖는 bounding box를 가정해보자. 이 앵커 박스를 슬라이드 시키면서, 백본 신경망으로부터 얻은 이미지 특징 grid의 모든 위치에 존재한다고 한다.
유일하게 끝까지 못 듣고 포스팅해버린 글..
내가 다시 끝까지 적으러 올 수 잇을까?
잘 몰르겟엉..
제송합니다 끊겼어요
이슈 많음 이슈
'EECS 498-007' 카테고리의 다른 글
| [EECS 498-007] Lecture 07. Convolutional Networks (2) | 2024.04.04 |
|---|---|
| [EECS 498-007] Lecture 16. Detection and Segmentation (1) | 2024.02.27 |
| [EECS 498-007] Lecture 14. Visualizing and Understanding (6) | 2024.02.18 |
| [EECS 498-007] Lecture 13-2. Attention (1) | 2024.02.12 |
| [EECS 498-007] Lecture 13-1. Attention (1) | 2024.02.11 |