나애 발표 강의 16강이당
마지막 cs 발표!
열심히 하고픈데
광양인 이슈로 공부를 못 하것다
어뜩해!
그래두 해야지.. 파이팅...
지난 포스팅에서 object detection에 대해서 이야기 했었다.
단일 RGB 이미지를 입력으로 받아 해당 이미지에 나타난 모든 객체에 대한 bounding box와 각 상자에 대한 카테고리 레이블을 출력해야 했다.
이어서 요번 포스팅도 OD에 대해서 다루고, Segemetation에 대해서도 다룰 예정이다.
먼저 object detection이 딥러닝에 얼마나 중요한 역할을 하는지! 를 알아보자.

이는 2007년부터 2015년 까지의 객체 검출에 대한 진전을 나타내는 그래프이다.
여기서 y축은 pascal VOC라는 특정 객체 검출 데이터 셋의 성능을 나타내고, 사용된 메트릭은 mAP이다.
2007~2010년에는 꽤나 지전이 있었지만 정체되다가, 2013년 처음으로 딥러닝이 적용된 결과 엄청난 향상을 보인다. 이 그래프는 2015년에 중단되는데, 실제로 pascal VOC 데이터셋이 그 당시에는 너무 쉬운것으로 간주되어 어려운 데이터 셋으로 전환되었다고 한다.

지난 시간에 처음 나온 상대적으로 느린 Slow RCNN과 convolution과 pooling의 순서를 바꾼 Fast RCNN의 버전도 보았다.
일부 정확도 향상 뿐만아니라 속도 향상도 가져왔었다.
지난 시간에 slow RCNN에 대해서 슈슉 지나간 느낌이 있다고 해서 요번 시간에 조금 더 자세히! 다뤄보겠다고 합니다.
train 동작 과정에 대해 다시 한 번 이야기해보자.

RGB input image와 물체를 포함하는 영역에 대한 정답 bounding box와 그 박스에 해당하는 카테고리를 얻게된다.
그 다음

입력 이미지 위에 일부 region proposals 방법을 실행하여 물체가 있을 것으로 예상되는 지역을 나타낸다.
예전에는 selective search와 같은 방법을 사용했지만 후에는 신경망으로 대체되었었다.
여기서 아주 중요한 과정이 있는데,

각 train을 반복하는 중에 각 region proposal이 positive인지, negative인지, neutral! 중립인지 결정해야 하는 것이다.
일부 region proposal은 실제 객체와 상당히 일치하는 것을 볼 수 있다. 특히 2개의 개와 고양이에 가깝게 region proposal이 존재한다.
하지만 첫번째 개를 보면 얼굴에 일부 교차하는 region proposal이 있으며, 배경에 속하는 의자에 일부에도 있는 것을 볼 수 있다. 따라서 이 의자의 경우 우리가 감지하려는 실체객체와 관련이 없어 positive와 겹치지 않는다.
즉 region proposal은 실제 정답 바운딩 박스에 상대적으로 가까운 것으로 분류해야한다. 가깝다면 Positive를 뜻하는 파란색 상자로 표시될 것이다. 이러한 근접함은 보통 일정한 임계값 이상의 교차 영역을 기준으로 측정된다.
일반적으로 교차영역이 0.3보다 작은 경우 negative로 분류되는데, 이러한 0.3과 같은 숫자는 hyperparameter라고 한다. 위 하늘색 상자와 같이 부정도 긍정도 아닌 중립인 경우가 생기는데, positive와 부분적으로 교차하면 부정적으로 분류되진 않으나 바운딩 박스와는 거리가 있어 양성으로도 계산하고 싶지 않은 경우라고 한다.

이렇게 하여 총 3가지의 범주로 나뉘게된다. 하지만 training시에는 일반적으로 중립 상자는 무시하고, CNN을 positive, negative로 학습시킨다고 한다.
그런 다음 이러한 것들을 훈련시킬 때, positive와 negative에 해당하는 모든 것들을 자른다. 이미지의 픽셀을 자르고 224 x 224와 같은 고정 크기로 변형시킨다. -> 이미지 분류 네트워크에서 사용되는 표준 해상도!

이러한 region proposal를 CNN에 통과시켜 class target을 예측하고, regression transform을 통해 box target을 알아낸다.
- positive proposal의 경우 class target은 개인지, 고양이인지 등을 의미하고, box target(bouding box와 같음)은 해당 positive proposal에 매칭되는 GT boxes를 의미한다.
- negative proposal의 경우 class target은 background로 출력하게 되고, 이에 해당하는 box target은 존재하지 않는다.
이 방식은 몇가지 단점을 가지고 있다.
- loss 계산이 복잡하다는 것이다. 이 CNN은 class target, box target이라는 두가지 결과를 산출하는데, 이는 곧 classification loss, regression loss라는 두가지 종류로 나뉜다는 것을 의미한다.
- classification의 경우 negative proposal 또한 background라는 레이블로 분류되기에 모든 proposal에 대해 loss가 존재하지만, regression transform의 경우 negative는 아예 결과를 낼 수 없기에 일부에 대해서만 loss계산이 가능해 복잡해진다.
- 하지만 여기서! 미니 배치 단위로 positive와 negative의 비율을 조정할 수 있다고 함! → 네트워크가 불균형한 클래스 분포에 대응할 수 있도록 도와주게 됨.
- classification의 경우 negative proposal 또한 background라는 레이블로 분류되기에 모든 proposal에 대해 loss가 존재하지만, regression transform의 경우 negative는 아예 결과를 낼 수 없기에 일부에 대해서만 loss계산이 가능해 복잡해진다.
- 너무 느려!
- 모든 proposal이 각각의 CNN을 통과하는 방식이므로 시간이 오래걸린다.
여기서 들 수 있는 의문은.. 우리는 어떻게 이러한 proposal에 label을 지정할 수 있을까? positive와 negative는 어떻게 결정될까?
이 해답은 매칭 단계에서 찾을 수 잇다. 우리가 region proposal을 가지고 있고, ground truth가 있는 경우, 이들을 교차 영역 기반으로 매칭할 때 이분 매칭을 사용한다고 한다. region proposal들이 있고 우리가 예측하려는 대상 객체들이 있을 때, 이들을 교차 영역을 기반으로 하여 짝을 이루어야 한다. 각 region proposal은 교차영역이 가장 높은 GT boxes와 짝을 이루게 된다.
그래서 positive label은 교차 영역이 가장 높은 곳에서 나오게 되는 것이다.
다음은 bounding box regression transform에 대한 트릭이 있다.
positive bounding box 마다 각 GT box와 짝을 이룬다는 점을 고려하면, 우리는 어떤 bounding box를 예측해야하는지 알 수 있게 된다. 그렇다면 positive bounding box를 transform의 목표로 사용하는 것이다.
근데 여기서 목표가 region proposal 에 매칭된 GT box에 의존하기 때문에 이를 train 전에 짝을 지어주어야 한다.
즉! 오프라인으로! 훈련중이 아닌 상태에서 train을 시작하기 전에 전체 데이터 셋에 대해 특정 작업을 완료하는 방식으로 진행된다.
하지만 Faster RCNN과 같은 모델에서는 region proposal을 나머지 시스템과 함께 학습하므로 짝지어주는 작업 중 일부를 온라인(train 도중에)에서 수행해야할 필요가 있다.
음 정리는 아니고 요약도 아닌 말을 하자면,
train과 test 모두 일관된 region proposal을 사용하여 bounding box를 생성하고, 학습된 regression transform을 test에 적용하여 최종 bounding box를 얻는 방식이라고 한다.!
📌 여기서 궁금한 점!
- 왜 train과 test에서 같은 region proposal을 사용할까? 다르면 우째되는디?
기계학습 모델 중에 가장 중요한 가정! 중 하나는 train과 test모두 입력되는 데이터의 유형이 유사하다는 것이다.
이 부분 역시 입력 부분이기 때문에 일관되게 적용해야 하는 것이다.
여기서 일관성을 검증하는 방법은 지난번에 언급했던 mAP를 사용한다고 한다.
- 📌📌 근데 여기서 정확도와 같은 다른 메트릭을 사용하지 않는 이유는 뭘까?
불균형한 클래스 문제에 대응하기 어려워! → 많은 양의 background box 때문에!
그니까 물체가 매우 적고 배경이 많은 경우, 단순히 모든 예측을 background라고 해버리면 정확도가 높아버리기 때문이다!
따라서 mAP를 사용해야 실제로 물체가 있는 경우에만 성공적으로 예측했다고 강조하게 된다.
다음은 Fast R-CNN에 대해서 다시 되돌아보자.

Fast R-CNN의 훈련 과정은 기본적으로 slow와 매우 동일하다.
주요한 차이점은 특징 추출과 crop의 순서를 바꾼 것이다. slow에서는 각 region proposal에서 독립적으로 픽셀을 crop했다.
하지만 fast에서는 전체 input image를 백본 CNN에 통과시켜 전체 고해상도 image feature를 얻은 다음, 이러한 피처에서 각 region proposal에 해당하는 부분들을 crop했다.
이 외에는 여전히! positive와 negative를 짝 지어주는 동일한 절차가 있다.
하지만 fast라고는 하는데.. Region proposal를 구하는 과정에서 계산 병목 현상이 발생한다는 문제가 있어, 속도 향상에 한계가 있었다. 그래서 사람들은 더 빠른! RCNN을 고민하기 시작해서 탄생한
Faster R-CNN

이 친구는 크게 두 단계로 이루어지는데,
첫번째 단계에서는
전체 이미지에서 fixed size의 anchor boxes를 생성하고, regression transform을 통해 region proposal boxes를 맞게 조정한다.
- anchor boxes
- bounding box(box target)와 헷갈리면 안됨! -> object detection의 결과기 때문에 모델의 '출력'!
- anchor boxes -> object detection을 통해 찾고자 하는 object의 대한 가정으로 모델의 '입력'!
- 그 사이즈는 하이퍼파라미터로서 우리가 설정할 수 있어 원하는대로 지정이 가능하다.
두번째 단계에서는
region proposal를 최종 output object boxes에 맞게 transform한다.

정리하자면
첫번째 단계에서 selective search가 아닌 anchor boxes를 이용한다는 점을 제외하면, 두번째 단계에서 region proposal를 GT box에 대응시키고, class target과 box target을 산출하는 과정은 동일하다.
이제 feature cropping을 하는 방법에 대해 다시 살펴보겠다.
지난 시간에 RoI Pool을 소개했었다.

이것을 수행했던 이유는 cropping operation의 결과로 산출되는 feature mapdmf network의 마지막 단계인 fully connected layer에 집어넣기 위해서는 일정한! 크기를 가져야 했기 때문이다.
하지만 두가지의 문제점이 존재했는데,

첫번째는 snapping에 의해 feature들이 사실은 잘못 정렬되었다는 것이다.
이때 snap은 input image를 feature map의 grid cell에 맞게 조정하는 과정인데, 이는 region proposal를 feature map의 grid cell에 딱 맞게 만들어줌으로써 결과적으로 우리가 원하는 크기, 즉 CNN 모델의 FC layer에 맞는 크기로 변형할 수 있도록 해주는 역할이다.
근데 이렇게 grid cell에 맞게 위치를 조정해주는 과정에서 원래 GT와 약간 맞지 않게 되어버린다는 것이다.
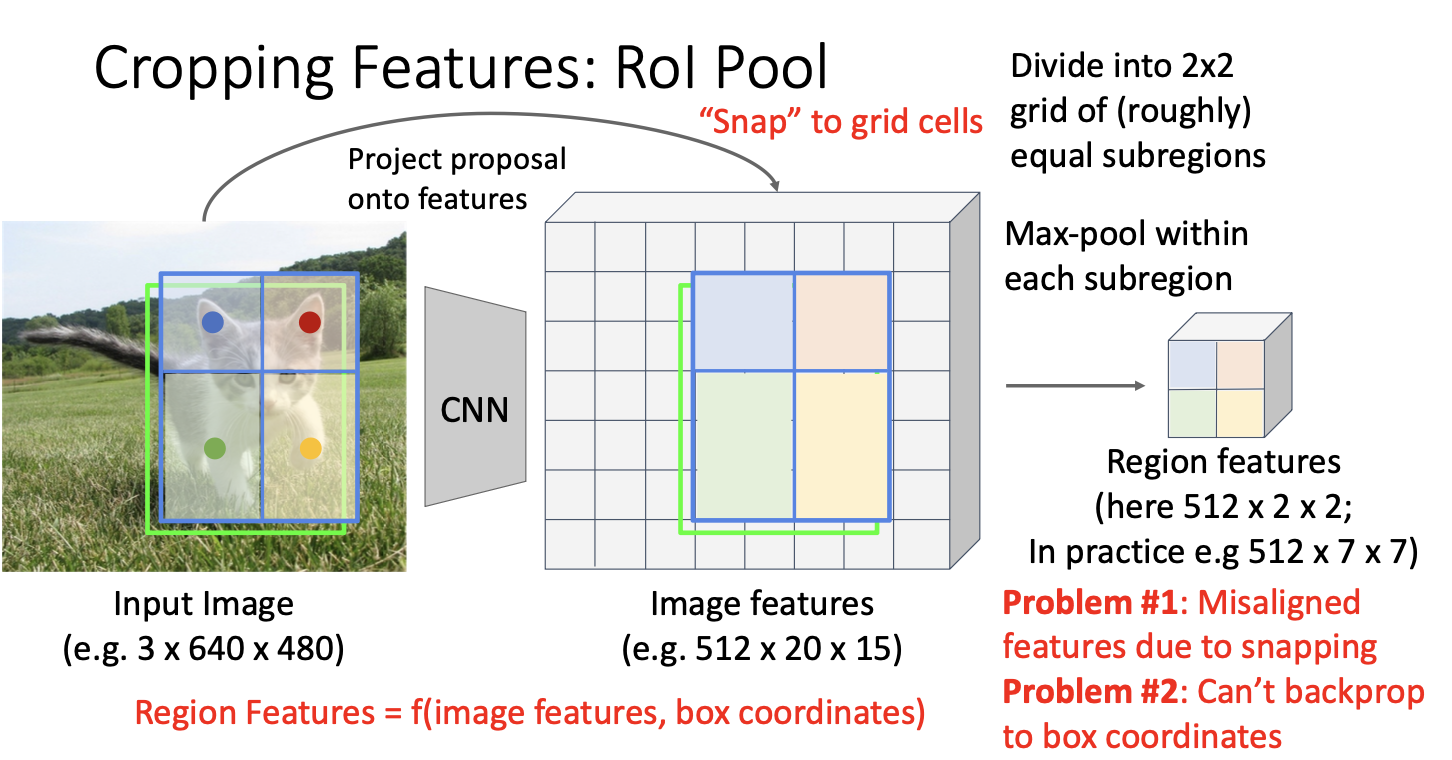
두번째는 이 또한 snapping과 관련된 것인데, 첫번째와 연결되는 문제라고 할 수 있다.
snapping 및 max pooling 결과 생성되는 region features는 원본 이미지에 대한 feature map과 crop하기를 원하는 bounding box를 토대로 만들어지므로, feature map과 bounding box를 input으로 하는 일종의 함수라고 생각할 수 있다.
그런데 여기서 snapping을 하면 RoI의 bounding box가 항상 grid cell에 맞춰지는 방식으로 변형이 일이나 기존 GT와 맞지 않게 되어 backprop이 불가능해진다.
즉 region feature로부터 feature map을 향한 backprop은 가능하지만, 연두색으로 표시된 원본 이미지의 bounding box를 향한 backprop이 불가능 하다는 것이다.
RoI에서 snapping 때문에 이러한 여러 문제를 발생시키자! snapping 과정을 없앤 RoI Align 이 등장한 것이다.
이것은 input image를 feature map에 projection 시키는 것 까지는 동일한데, 이후 snapping 과정을 없애고 다음과 같이 동작한다.
RoI Align


먼저 projection을 통해 생성된 RoI를 우리가 만들고 싶은 region feature의 크기에 맞춰 등분해준다.
예시에서 보면 2 x 2 크기의 region feature를 생성하고자 하므로 위와 같이 4등분 하면 된다.
그러고 난 뒤에는 연두색 점으로 표시된 sample point들을 잡는다. 4등분한 각각의 subregions별로 같은 간격으로 균일하게 퍼지게끔 잡으면 된다. 그러고 난 뒤, sample point마다 쌍선형 보간법(bilinear interpolation)을 적용하여 sample point가 하나의 값, feature를 갖도록 만든다.
📌 여기서 궁금한 점!
- 쌍선형 보간법이 뭐야?
일단 보간법! 은 이미 알려진 값들을 활용하여 원하는 위치에서의 값을 추정하는 방법의 종류! 인데,
1차원 공간에서 사용하는 선형 보간법을 2차원 공간에서도 사용하기 위해 확장한 것!
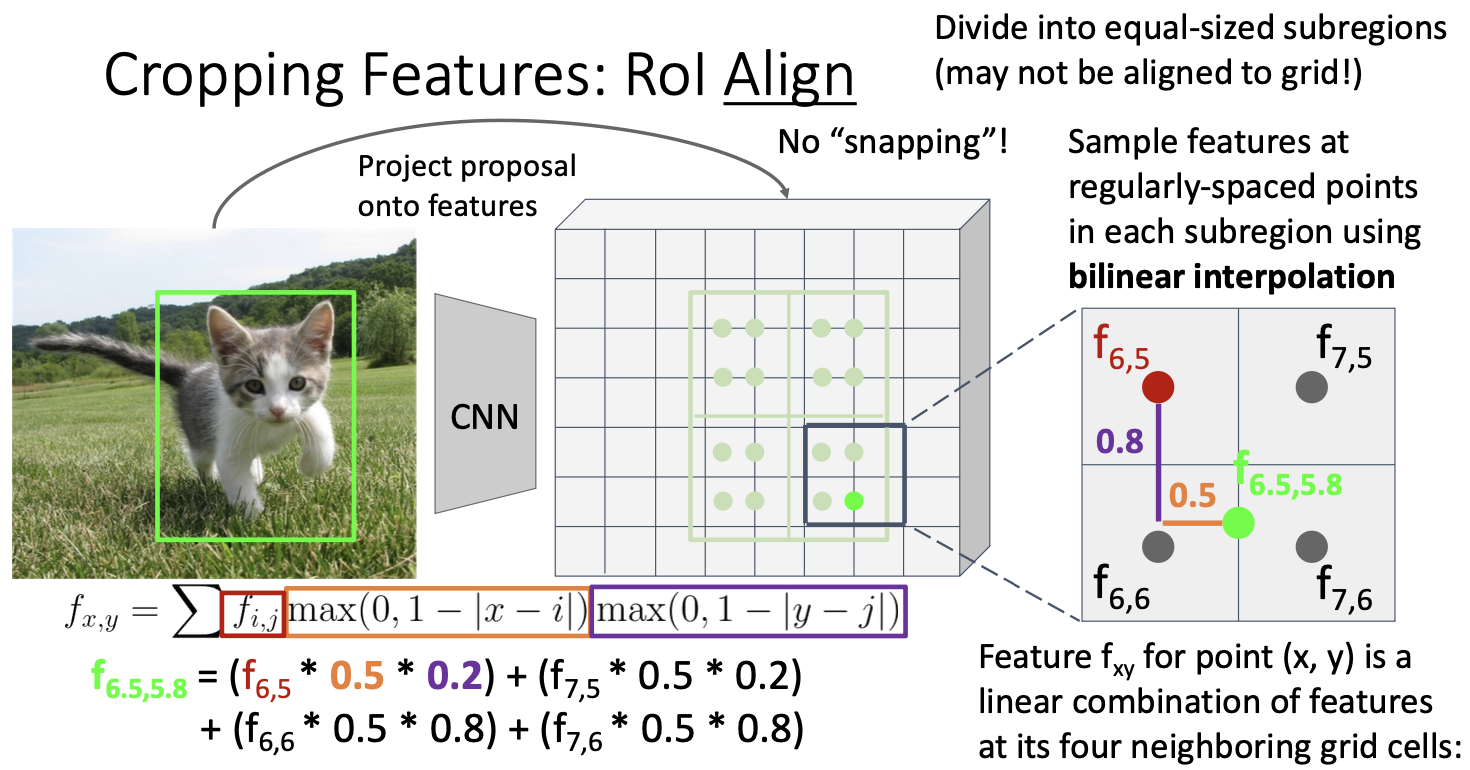
쌍선형보간법을 하는 과정을 좀 더 자세히 보면, 보간을 할 때는 위 그림과 같이 해당 sample point를 기준으로 가까운 4개의 grid cell의 feature 값들을 이용한다. 가까운 거리의 feature에 더 큰 가중치를 주는 방식으로 feature 값을 더하는 방식으로 보간이 이루어지며, 그 식은 좌측 하단과 같다.

그렇게 모든 계산이 끝나고 나면 연두색 점으로 표현된 각각의 sample point는 각기 하나의 feature 값을 가지게 되고,
average pooling 또는 max pooling을 이용해 최종적으로 우리가 원하는 Region features 사이즈인 2 x 2로 축소하게 된다.
지금까지 배운 내용을 정리하자면! OD Methods 에는

R-CNN, Fast R-CNN, Faster R-CNN, Single stage 등이 있다.
faster과 single이 가장 발전된 형태라 볼 수 있는데, 둘다 anchor box와 연관되어 있다는 공통점이 있다.
그래서 여기서 든 의문이! anchor box가 없어도 detection을 할 수 있는 방법이 있을까?
CornerNet

요러한 질문에서 나온 것이 CornerNet이다!
지금까지와는 조금 상이한 방식으로 bounding box를 만드는데, 위 그림과 같이 왼쪽 위와 오른쪽 아래 코너의 point pair를 통해 bounding box를 표현한다.
왼쪽 위, 오른쪽 아래 코너를 정할 때는 각 object 별로 어떤 픽셀이 해당 코너로 적합한지에 대한 확률을 계산해서 결정한다.
먼저 image level features를 얻기 위해 백본 CNN에 input image를 넣는다. 이렇게 생성된 image features에서 우리가 예측하고자 하는 각각의 object별로 왼쪽 위와 오른쪽 아래 코너에 대한 heatmap을 그린다.
이를 통해 feature map의 모든 위치 중에서 왼쪽 위 코너, 오른쪽 아래 코너가 될 확률을 계산하고, 각 픽셀에 대해 cross entropy loss를 구함으로써 해당 과정을 train하게 된다.
그치마나 여기서 왼쪽 위, 오른쪽 아래 코너 각각을 찾는 것에서 끝이 아니라, 각각의 코너를 서로 매칭시켜 하나의 bounding box를 이룰 수 있도록 해야한다. 따라서 모든 위치에 대해 embedding vector를 함께 예측하고, embedding vector가 비슷한 왼쪽 위, 오른쪽 아래 코너끼리 짝을 짓게 된다.
지금까지는! 15강에 이어서 Object Detection에 대해서 복습? 추가? 설명을 하였다.
드디어 computer vision의 또 다른 중요한 task인 Segmentation 방법을 소개하겠다.
Semantic Segmentation

이것은 input image의 모든 픽셀을 카테고리 label로 지정하는 것이다.
예를 들어 새끼 고양이가 풀 위를 걸어다니는 이미지의 경우, 시스템이 인식하는 일정한 카테고리 세트에 속하는 모든 픽셀을 고양이, 풀, 나무, 하늘 등으로 레이블링 하고자 하는 것이다.
이 작업에서 중요한 점은 이 작업이 서로 다른 객체 인스턴스에 대해 인식하지 않는다는 것이다.
이 말이 잘 안 와닿을 수 있으니 뒤에 나오는 개념을 먼저 익힌 뒤 다시 읽어보자!

발표자료 뒤에 보면 things와 stuff에 대한 정의를 내린다. object는 크게 두가지로 분류될 수 있는데,
- things : 인스턴스로 나뉠 수 있는 object → 고양이, 자동차, 사람 등
- stuff : 인스턴스로 나뉠 수 없는 object → 하늘, 풀, 나무, 물 등
즉 위의 말은 이미지의 모든 픽셀에 레이블을 지정하는 것으로 동일한 카테고리에 속하는 두 객체가 서로 인접해있다면! 위의 사진의 경우 소가 그 예가 되겠다. 그 경우에는 두 인스턴스를 구별하지 않고 단순히 모든 픽셀을 cow! 라고 labeling 하게 된다.
지금부터 다룰 Sementic segmentation이 어떤 방식으로 동작하는지 알아보자.

그 방법은 다시 sliding window를 사용하는 것이다. 모든 픽셀에 대해 이미지에서 작은 패치를 추출하고, 해당 패치를 CNN에 넣어 카테고리 레이블을 예측할 수 있다. 모든 픽셀 주위에 패치를 추출하여 이를 반복함으로써 이 작업을 수행할 수 있다.

하지만 이 방법은 알다시피! 매우 느리고 비효율적이다. 실제로도 이 방법을 사용하진 않는다.
대신 이 task에서 흔히 사용되는것은 FCN이다.
FCN : Fully Convolutional Network

이는 pooling layer를 갖지 않는, 단순히 convolution layer로만 이루어진 구조이다. input image는 고정된 공간 크기의 이미지로 주어지며, 최종 출력은 각 픽셀에 대한 class 점수의 집합이다.
예를들어 3 x 3크기와 strid 1, pad 1인 layer를 쌓는다고 생각해보면, 출력은 입력과 동일한 공간 크기를 가지게 된다.
최종 layer의 출력 채널 수를 우리가 탐지하고자 하는 카테고리의 수와 동일하게 설정하고, 그에 대한 출력을 각 픽셀에 대한 각 카테고리 스코어라고 해석할 수 있다. 그 다음 softmax를 적용하여 이미지 내 각 픽셀에 대한 레이블의 확률 분포를 얻을 수 있는 것이다.
여기서 드는 의문!
카테고리가 몇 개인지 어떻게 알아?
train을 할 때, 이미지 분류와 마찬가지로 미리 정의된 일련의 카테고리를 선택하게 된다. 시스템이 인식해야 할 몇 가지 고정된 카테고리가 있을 것이며, 이는 train data set에 따라 결정될 것이다.
객체 탐지와는 달리 변한 크기의 대한 출력 문제는 없다. 그 이유는 시스템이 인식하는 고정된 카테고리 수를 알고 있으며, 각 픽셀에 대해 객체 카테고리에 대한 예측을 하려고 하기 때문이다.
따라서 출력의 크기는 입력의 크기에 의해 완전히 결정되게 된다. 그 이유로! cross-entropy loss를 사용할 수 있게 된것이다.
하지만 또 이 구조에 대해서는 문제점이 있다!

첫번째 문제는
receptive filed size가 선형적으로 증가한다는 것이다.
예를 들면 우리가 3x3 컨볼루션을 여러개를 쌓는다고 상상해보자 (strid1, pad1) 두 개의 3x3 컨볼루션을 쌓게되면 두 번째 layer의 출력은 사실상 입력의 5x5 영역을 보게되고, 세 개의 3x3 컨볼루션을 쌓으면 출력은 입력의 7x7 영억을 보게되는 것이다.
즉 이것은 큰 receptive filed를 얻으려면 매우 많은 layer가 필요하다는 것이다.

두번째 문제는
높은 해상도 이미지를 요구하기에 계산량의 문제이다.
원본 이미지의 해상도에서 모든 이 컨볼루션을 수행하는 것은 계산적으로 비실용적이다.
그래서 결과적으로 이것을 사용하는 사람은 없답니다. ... (아깐 있다며..?)
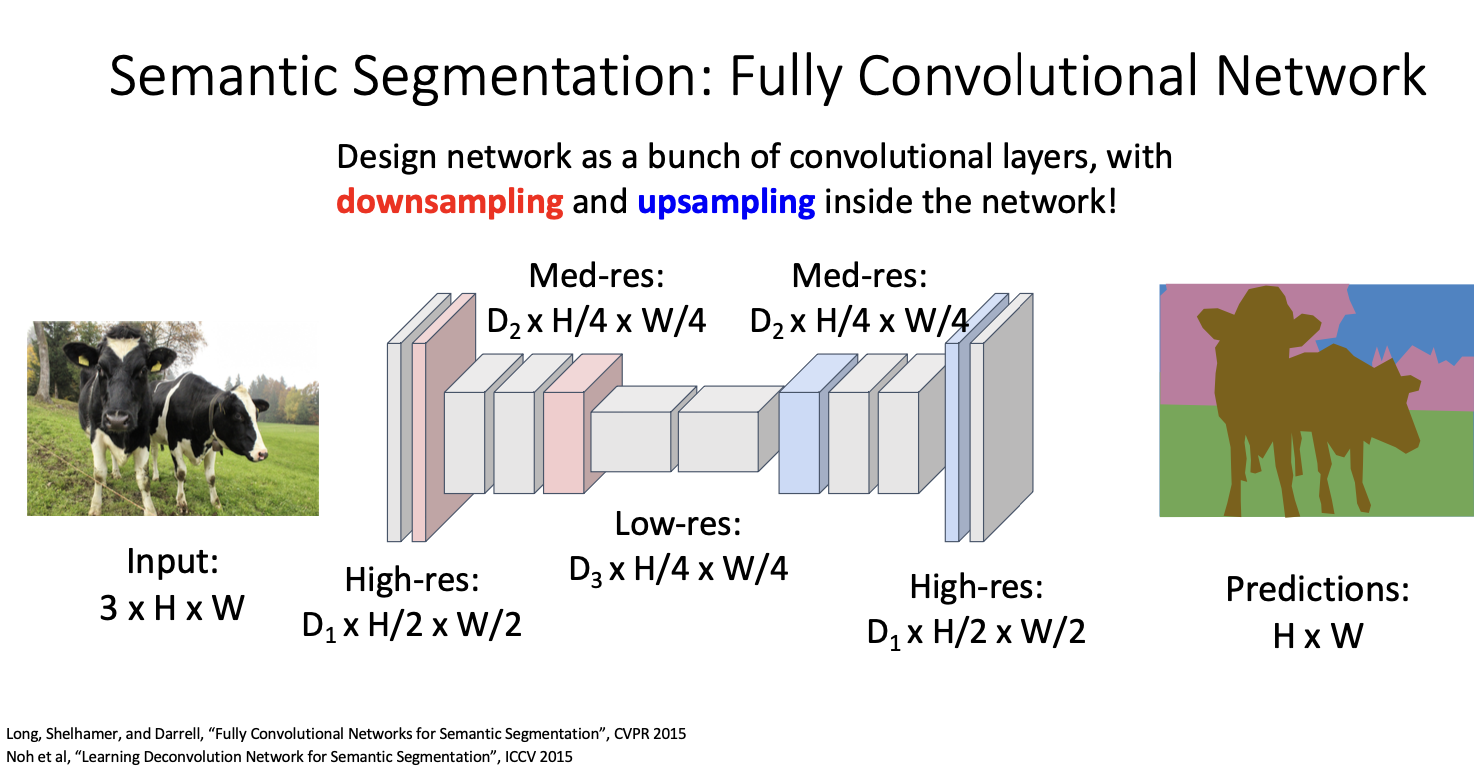
대신 downsampling과 upsampling의 형태를 가진 아키텍처를 더 자주 볼 수 있다고 한다.
이 아키텍처의 장점은 두가지인데,
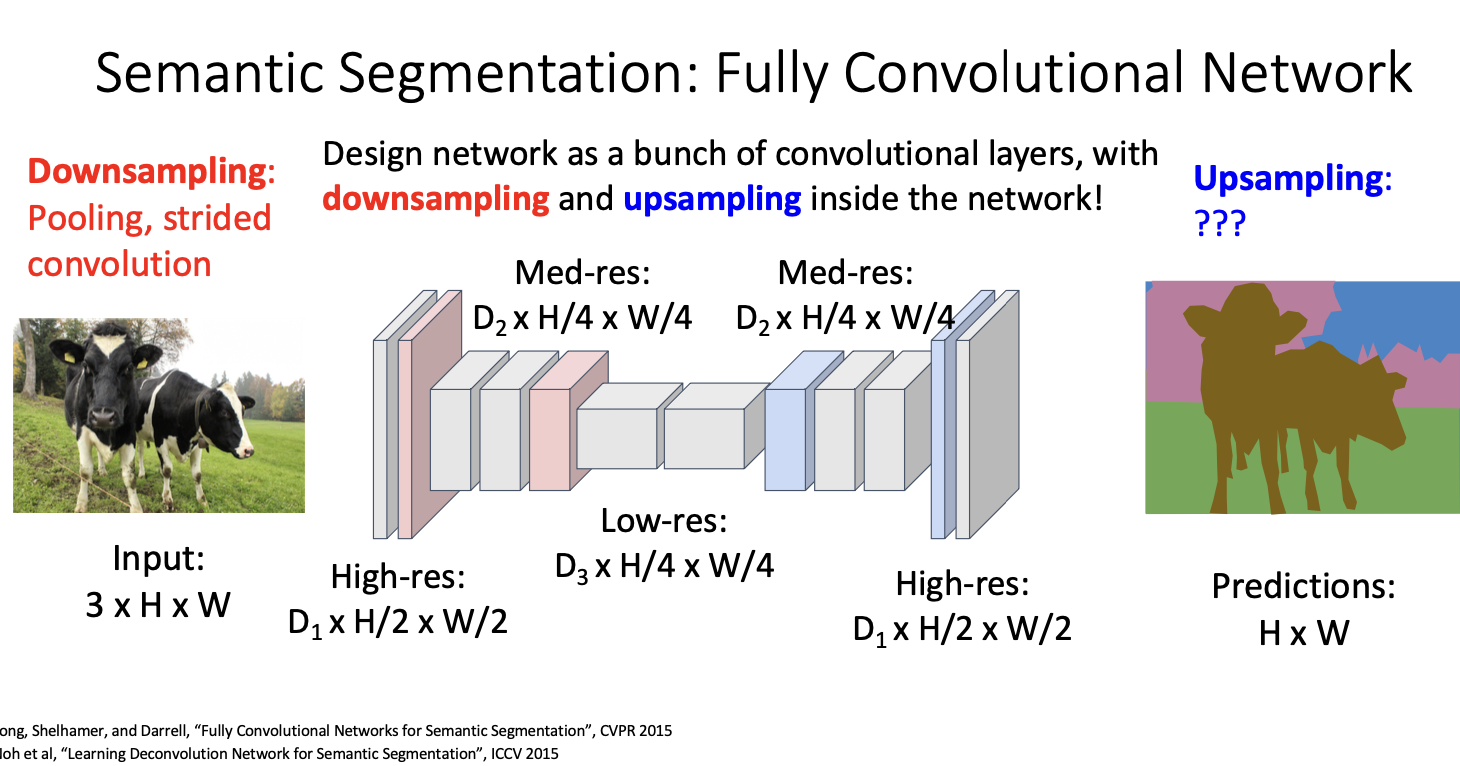
- downsampling은 이미지 분류에서와 같이 계산적으로 효율적이다.
- pooling이나 stride와 같은 기술을 사용하여 공간적 차원을 효과적으로 줄인다.
- downsampling으로 인해 receptive filed가 더 빠르게 커질 수 있다고 한다.
또 downsmapling이 아닌 신경망 내에서 upsampling을 수행하는 몇가지 방법들에 대해서 살펴보자.
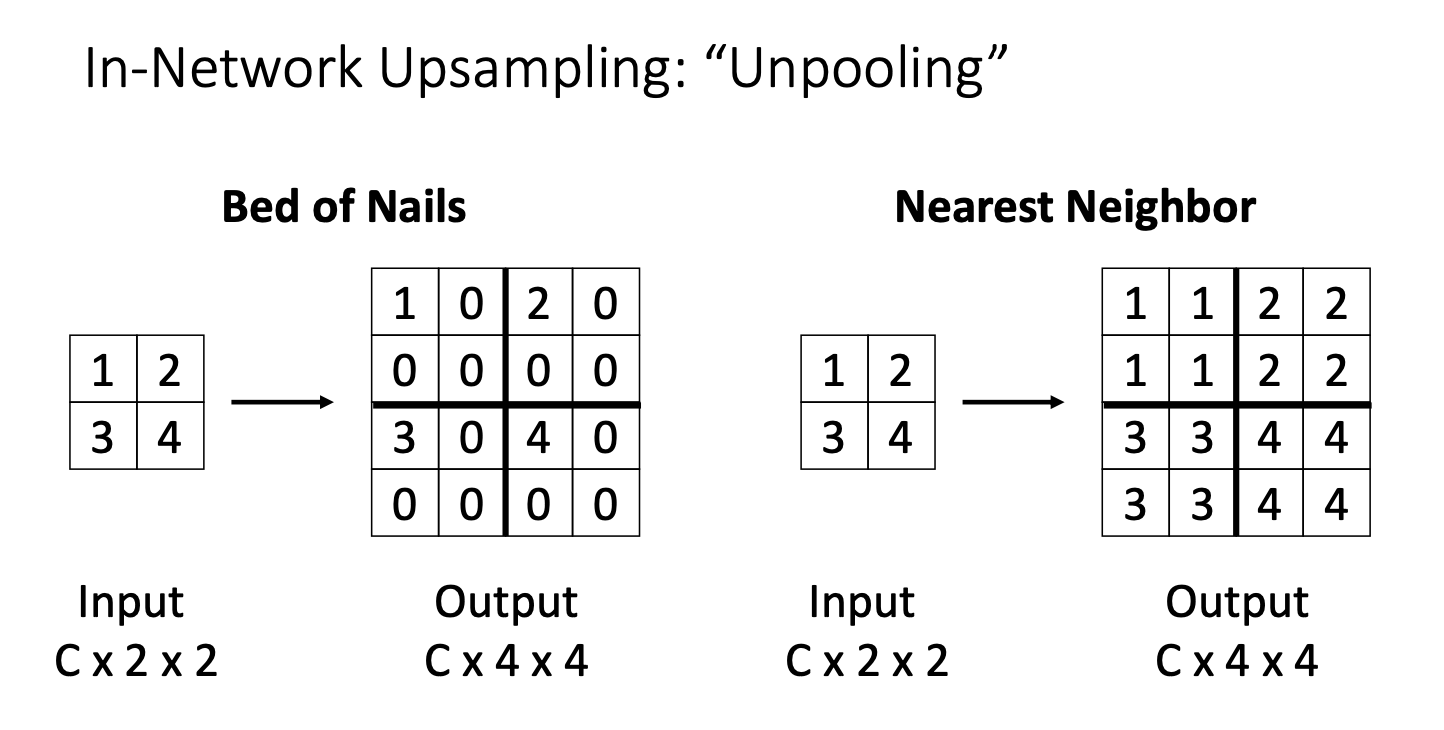
upsampling은 pooling의 반대개념이기 때문에 unpooling이라고도 불리는데, 두가지 방법이 있다.
여기서 입력은 공간크기와 채널 수가 각각 2x2인 이미지라 가정, 목표는 각 위치에서 동일한 채널 수를 유지하면서 공간적으로 두 배 큰 출력을 생성하는 것.
- Bed of Nails
- 출력을 모두 0으로 채우고, 각 입력 영역의 특지이 벡터를 해당하는 출력 영역의 좌 상단에 복사하는 방식
- 어디에나 0이고, 특징 벡터가 복사된 곳에 못이 있는 것처럼 생겼다 해서 bed of nails라고 붙여졌다고 한다.
- 좋은 아이디어는 아님! 실무에서 사용하지 않아.
- Nearest Neighbor
- 각 특징 벡터를 복제하여 입력에서 각 위치에 대해 고정된 횟수로 복사하는 방식
Bilinear Interpolation

또한 우리는 RoI align 작업 내에서 양선형 보간에 대해서 설명했다. upsampling에서도 이를 사용할 수 있는데,
여기서는 입력이 C 채널과 2x2 크기의 공간을 가지고 있다고 가정하고, 입력 특징 그리드에 균일하게 4x4 그리드를 배치한다고 가정하자.
그 다음 4x4 samplig grid의 각 지점에 대해 양선형 보간을 사용하여 출력 특징을 계산할 수 있다.
Bicubic Interpolation

bicubic 보간은 쌍입방 보간으로 16개의 가장 가까운 인접 픽셀의 가중 평균을 취하여 각 새 픽셀의 값을 추정하는 방식이다.
가중치는 새 픽셀과 주변 픽셀 사이의 거리를 기준으로 결정되며 가까운 픽셀이 더 높은 가중치를 갖는다.
선형 근사치보다 부드러운 근사치를 얻을 수 있으며 일반적으로 이미지 크기를 조절할 때, 브라우저나 이미지 편집 프로그램에서 이 방법이 사용된다고 한다.
위와 같은 방법들은 모두 비교적 간단한 upsampling 방법으며, 표준 프레임워크인 pytorch, tensorflow 등에서 일반적으로 구현되어있다고 한다.
조금 더 독특한 방법 중 하나는 max pooling의 반대 개념인 max unpooling 이라고 한다.
Max Unpooling

이 아아디어는 upsampling 연산이 네트워크 내에서 독립적인 연산이 아니라, 실제로는 네트워크 내에서 이전에 수행된 downsampling 연산과 결합된다는 것에서 시작한다.
max pooling으로 downsampling을 수행할 때, 각 격자 내에서 최댓값이 발생한 위치를 기억하게 되며, unpooling 시에는 이러한 위치 정보를 활용하여 각 위치에 대해 최댓값을 설정하는 방식으로 동작한다. 이는 bed of nails의 방법과 유사하지만! 각 feature vector를 특정위치에 배치하는 대신, 최댓값을 해당 위치에 적용하는 것이다.
그럼 이렇게 하는 이유는! bad of nails에 비해서 정보 손실을 방지할 수 있으며, 별도의 메모리를 필요로하지만 CNN에선 매우 작은 비율이므로 크게 상관이 없다고 한다.
여기서 규칙은 만약
- downsampling: average pooling을 사용했다면, upsampling: nearest neighbor나 bilinear, bicubic
- downsampling :max pooling을 사용했다면, upsampling: max unpooling
따라서 upsampling은 downsampling의 특성에 따라 결정되곤 한다!
여기서 이들은 모두 leanable parameter를 가지지 않는 고정된 함수이다. 하지만 leanable parameter를 가지는 형태의 연산을 사용하기도 하는데! 이것이
Transposed Convolution
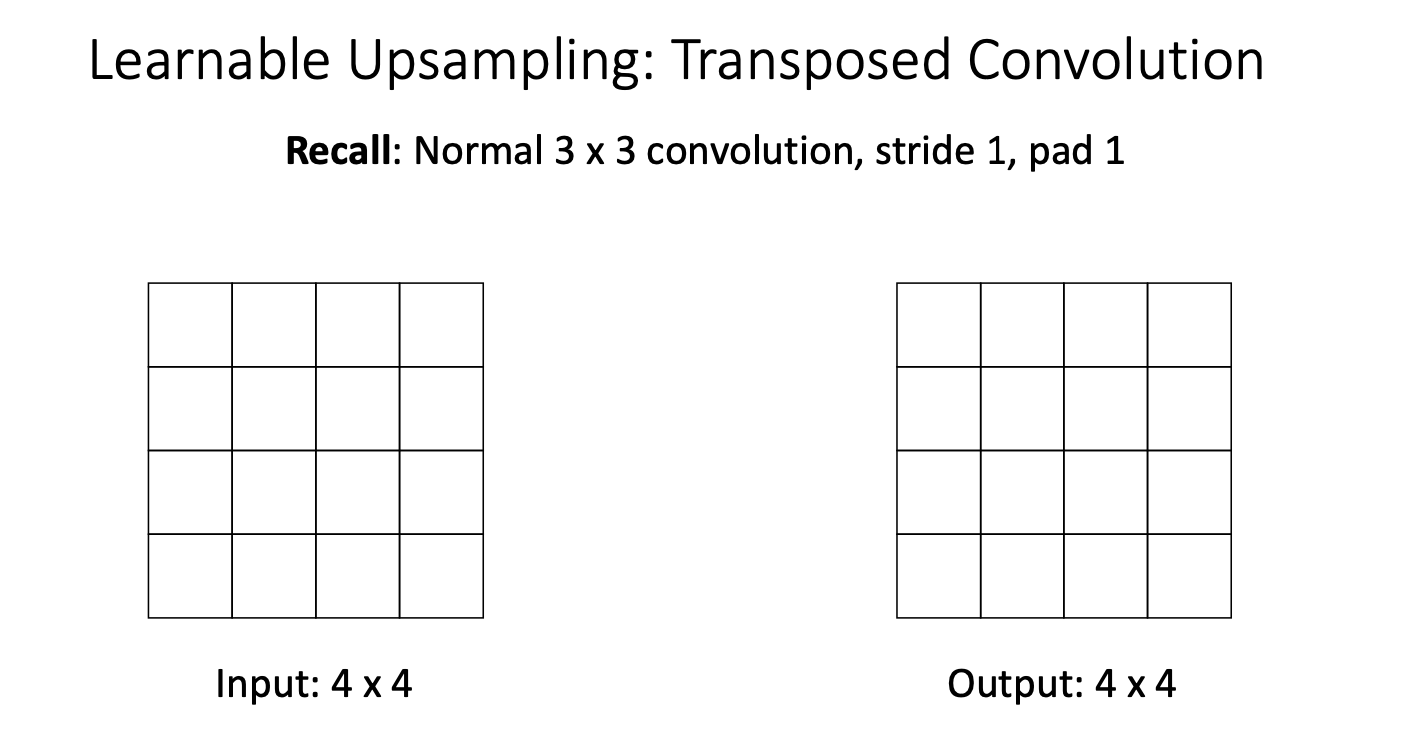
이 trasnposed conv를 이해하기 위해 일반적인 컨볼류션 작동 방식을 되짚어보자!

3x3 크기의 stirde1, pad1 을 가진 컨볼루션을 생각해보자.
그러면 출력의 각 위치는 필터와 입력에서의 어떤 공간 영역 간의 내적된 결과이다. 그리고 stride가 1이므로 출력에서 이동할 때마다 입력에서 한 위치씩 이동하게 된다.
다음 stride를 2로 설정하여 다시 적용해보자.


stride가 2라면 출력에서 한 위치를 이동할 때마다 입력에서 두 픽셀을 이동하게 된다.
따라서 일반적인 컨볼루션에서 stride를 1보다 크게 설정하면 이 비율 때문에 입력 feature map이 downsampling이 된다.
근데 여기서 stirde를 1보다 작게 설정하고, 입력에서 여러 위치를 출력에서 여러 위치로 이동하는 방법이 있을까?
그런 방법이 있다면! 그것은 leanable한 upsampling 연산이 되어 학습을 할 수가 있는 것이다. 그것이 바로 전치 컨볼류션!

입력은 2x2의 크기, 출력은 더 높은 해상도의 4x4크기가 된다고 가정하자.
우리는 3x3의 필터를 가지고 있고, 이 필터를 입력 텐서의 각 원소에 곱하여 입력 값과 필터 값 사이의 스칼라 텐서 곱을 수행한다.
다음 이 가중치가 적용된 필터의 복사본을 출력의 해당 위치에 복사하게 된다.

두번째 위치에서는 다시 필터 값을 가지고 와서 두번째 파란 픽셀을 가중치로 적용한 후에 입력을 필터 값으로 곱하고 가중치가 적용된 필터를 출력의 해당 위치로 복사하게 된다.

여기서 두가지 다른 필터 값에서 나온 출력이 겹치는 두 영역에서는 겹치는 부분을 합산하게 된다.
입력의 각 2x2 영역에 반복하면 3x3 영역의 겹치는 합으로 이루어진 5x5 출력이 생성되는 것을 볼 수 있다. 이 두 행과 열을 자르면 4x4 출력을 얻을 수 있으며, 이것을 자르는 연산은 패딩과 유사하다.
이것을 좀 더 구체적으로 살펴보면,

입력은 길이가 2인 벡터이고, 필터는 길이가 3인 필터이다. 여기서 출력을 계산해야 하는데,
필터 xyz를 첫번째 위치에서의 입력 값 a와 곱한 다음, 이를 출력의 세 위치에 복사하는 것이다. 그런 다음 입력에서 한 위치를 이동할 때마다 출력에서는 두 위치를 이동하게 된다.
이제 두번째 위치에서는 다시 필터 값을 가져와서 입력의 값(b)으로 가중치를 적용하고 이를 출력의 이동된 위치에 복사한다.
이 겹치는 영역에서는 합을 하게 되는 것이다. (az + bx)
실제로 논문을 읽으면 이 작업에 대해 저자들이 서로 다른 이름을 부르는데,

- deconvolution 라고도 부르는데,
- 이는 기술적으로 정확하지 않은 것이라 한다.
- upconvolution
- fractionally strided convolution
- 이것은 분수 stride와 같이 보이기 때문! 대충 stride가 1보다 작다는 뜻
- backward stride convolution
- 실제로 transposed conv는 forward가 stride conv의 backward와 동일하기 때문에
- transposed convolution
- 강사가 가장 좋아하는 이름! 그리고 커뮤니티에서 보통 이것으로 자주 불러!
- 그 이유는 conv연산을 행렬 곱으로 표현할 수 있기 때문! 밑에 한 예를 보자!
- 강사가 가장 좋아하는 이름! 그리고 커뮤니티에서 보통 이것으로 자주 불러!

이것은 1차원의 예시로, 3개의 원소로 이루어진 벡터 x, y, z가 주어지고, 이 벡터가 필터 a, b, c, d와 conv된다고 가정하자.
결과적으로 출력은 우리가 익숙한 zero padding이 적용된 일반적은 컨볼루션 연산이다.
하지만 이 연산을 transposed matirx multiply로 수행할 수 있다.

왼쪽의 행렬을 따라 벡터를 대각선으로 복제한 다음, 이 행렬과 입력 벡터의 일부를 곱하는 행렬-벡터 곱셈을 수행하여 전체 연산을 수행할 수 있다. 이것은 전치된 X행렬을 사용하는 것을 의미한다.
근데 여기서 stride 1 transposed는 기본적으로 동일한 종류의 conv에 해당하는 것을 알 수 있다. 단, 패딩 적용의 차이가 있을 수 있으나! 수학적으로는 동일하다는 것!
그렇다면 stride가 1이 아니면 ?

왼쪽에 stride가 2인 conv 예제를 나타내고 있다. 이제 오른쪽에는 동일한 연산으로 transpose를 하여 conv 연산을 할 것인데

stride 가 2인 경우에 희소성 패턴이 매우 다르다는 것을 볼 수 있다.
그리고 이러한 방식으로 바라본다면, conv의 역전파를 유도하는 또 다른 쉬운 방법이 될 수 있다.
transposed conv의 forward가 일반 conv의 backward와 동일하다는 것을 확인할 수 있다. 그래서! 이 두가지 사이의 또 다른 대칭성을 보여준다고 할 수 있다.

이것은 실질적으로 sementic segmentation에 대한 설명이다.
결국 downsampling과 upsampling이 포함된 네트워크를 구축할 수 있고, 픽셀 당 손실함수로 cross entropy를 사용하였다.

우리는 개별 객체 인스턴스를 감지하고 주위에 바운딩 박스를 그리는 object detection에 대해서도 이야기 했으며,
픽셀당 레이블을 제공하는 sementic segmentation에 대해서도 이야기 했다.
그러나 후자의 경우 서로 다른 객체 인스턴스를 인지하지 못하는 문제점이 있었다.
이 문제는 어떻게 극복할까?

위에서 언급했던 things와 stuff의 개념을 다시 상기시키고 가자!
things는 개, 고양이, 사람과 같은 물체에 속하는 것, stuff는 하늘, 풀, 물 등 물질에 속하는 것이였다.
여기서 언급되었던 문제점이 OD의 경우 주로 물체만 처리하고 개별 인스턴스를 구별해야하기에 문제점이 생겼고,
Sementic segmentation의 경우 물체와 물질 모두 다루지만, 개별 물체 인스턴스의 개념을 버리는 문제점이 있었다.
그래서 등장한 것이!
Instance Segmentation

이 작업은 사실상 od와 sementic segmentation을 결합한 것으로, 각 검출된 객체에 대해 해당 객체의 segmentation 마스크를 출력한다. 이것은 주로 things에만 적용되며, 즉 개별 물체 인스턴스에 대해 의미있는 유형의 객체만 적용된다.

위 그림과 같이 두 소에 대한 instance segmentation을 수행하면, 각 검출된 소에 대해 이미지의 어느 부분이 소에 속하는지를 나타내는 2개의 소 segmentation 결과가 나올 것이다!

이를 구현하기 위해서는 mask R-CNN을 이용해야 하는데, 이는 faster R-CNN과 구조가 매우 흡사하나! 우리가 detect한 object들에 대해 segmentation을 수행하는 'mask prediction' branch가 추가되었다는 차이점이 존재한다.
Mask R-CNN

Mask R-CNN은 faster R-CNN과 비슷한 구조를 가진 만큼 동작과정도 유사하다.
image level features를 얻기 위해 Input image를 백본 CNN에 집어 넣는다는 점, region proposal network를 통과한다는 점과 각 region proposal에 대해 feature map을 얻기 위해 RoI Align을 수행한다는 점은 od과정과 동일하다.

이후 segmentation mask를 예측하기 위해 앞서 과정을 통해 detect한 object에 대해 sementic segmentation network를 수행하게 되는데, 이것도 위에서 언급했던 내용과 같다. 차이점을 말하자면, 전체 input image가 아니라 od를 통해 추출한 object에 대해서만 sementic segmentation을 수행한다는 것이다.
크게 본다면 faster R-CNN 위에 하나의 추가 헤드를 연결하여 각 영역에 대해 추가적인 예측을 수행하는 것이다.
즉 지금까지 배운 object detection과 sementic segmentation의 조합이라고 보면 된다.
몇가지 예를 들어 살펴보자.

위 그림은 segmentation mask의 training target이 bounding box에 따라 달라지는 것을 볼 수 있도록 해주고 있다.
bounding box가 의자 크기에 딱 맞게 생성되었을 대는 위와 같은 형태로,
bounding box가 조금 더 여백을 두고 생성되었다면 아래와 같은 형태로 segmentation이 이루어 진다.

또한 segmentation의 결과는 object의 카테고리 레이블에 따라서도 달라지는데,
segmentation하고자 하는 object를 소파로 잡았을 때는 위와 같은 형태로,
object를 사람으로 잡았을 때는 아래와 같은 형태로 segmentation이 이루어진다.

mask R-CNN을 사용했을 때 instance segmantation의 결과가 매우 좋은 것을 확인할 수 있다.
여기서 부터는 좀 더 발전된 형태의 segmentation task를 가볍게 소개하겠다.

semantic segmentation과 instance segmentation을 합친,
Panoptic Segmentation

things와 stuff 모두에 대해서 labeling을 해주면서 각각의 instance를 구분까지 할 수 있는 panoptic segmentation도 존재하는데,

성능이 매우 좋다고 한다.
또 다른 흥미로운 task중 하나는 key point 추정이라고 하는 것이다.
key point estimation

특히 사람에 대해서 segmentation하는 것 중에 그들의 포즈를 보고 디테일하게 분석하려는 시도를 중 하나이다.
여기서도 R-CNN이 좋은 성능을 말휘하는데,

mask R-CNN을 keypoint estimation에 활용하기 위해서 keypoint prediction 을 추가한 모양이다.
모델의 동작 방식은 mask R-CNN과 동일하지만, sementic segmenation mask 대신, k개의 keypoints에 대한 Keypoint mask를 활용한다는 차이점이 있다고 한다.
보통 귀, 코, 눈 및 모든 관절과 같은 일련의 keypoint를 정의하고, 각 사람의 각 키포인트의 위치를 예측하려는 것이다.

각 keypoint에 대해 예측된 segmentation mask를 corss entropy loss를 사용하여 모델을 train하게 된다.

이러한 방식을 사용하면 위와 같은 놀라운 결과를 얻을 수 있다.
교실에 앉아있는 모든 사람들을 감지하고 각 사람에 대한 정확한 자세들을 알려주고 있다.
우리는 이제 알았어!

어떤 cv 작업에서든지 입력 이미지의 다른 영역에 대해 예측하고 싶을때, 이를 object detection으로 해겷ㄹ 수 있고,
더하여 추가적인 head를 통해 우리가 원하는 새로운 유형을 얻어낼 수 있다.
또 다른 멋있는 예로, 동적 캡션! 이라는 개념이다.

실제로 객체 감지기와 이미지 캡션을 통합한 후 입력 이미지의 여러 영역에 대해 자연어 스크립트를 출력하고 자하는 것이다.
이것은 추가적인 head 부분에 LSTM이나 다른 종류의 caption 모델을 추가하여 수행할 수 있는 작업이다.


위와 같이 작업이 진행되며 실시간으로 자연어로 바꾸어주는 것도 볼 수가 있다.
또한 2D image로 부터 3D shapes를 생성해내는 기술도 개발되었다고 한다. (존슨 교수님 본인이직졉)


이는 mask R-CNN에 mash head를 결합함으로써 각 영역마다 3D 형태를 예측하는 방법이라고 한다.
이 부분에 대해서는 다음 강의에서 더 자세히 다루겠다고 합니당! (드디어 끝이 보인다)
드디어 오늘의 썸머리!

사진으로 대체하겠다..
흐어 무호흡으로 달린 16강 이었다.
내 발표라 그런지 또 꼼꼼히 듣느라
1시간짜리 강의지만..
8시간은 걸린 것 같습니당..
윤수많!
아니 아직 수고 많으려면 멀었지......
부족한 점이 많아요
'EECS 498-007' 카테고리의 다른 글
| [EECS 498-007] Lecture 07. Convolutional Networks (2) | 2024.04.04 |
|---|---|
| [EECS 497-998] Lecture 15. Object Detection (6) | 2024.02.26 |
| [EECS 498-007] Lecture 14. Visualizing and Understanding (6) | 2024.02.18 |
| [EECS 498-007] Lecture 13-2. Attention (1) | 2024.02.12 |
| [EECS 498-007] Lecture 13-1. Attention (1) | 2024.02.11 |